4. Mapping Refinement Steps
During the mapping process, the abstract workflow undergoes a series of refinement steps that converts it to an executable form.
4.1. Data Reuse
The abstract workflow after parsing is optionally handed over to the Data Reuse Module. The Data Reuse Algorithm in Pegasus attempts to prune all the nodes in the abstract workflow for which the output files exist in the Replica Catalog. It also attempts to cascade the deletion to the parents of the deleted node for e.g if the output files for the leaf nodes are specified, Pegasus will prune out all the workflow as the output files in which a user is interested in already exist in the Replica Catalog.
The Data Reuse Algorithm works in two passes
First Pass - Determine all the jobs whose output files exist in the Replica Catalog. An output file with the transfer flag set to false is treated equivalent to the file existing in the Replica Catalog , if the output file is not an input to any of the children of the job X.
Second Pass - The algorithm removes the job whose output files exist in the Replica Catalog and tries to cascade the deletion upwards to the parent jobs. We start the breadth first traversal of the workflow bottom up.
( It is already marked for deletion in Pass 1
OR
( ALL of it's children have been marked for deletion
AND
( Node's output files have transfer flags set to false
OR
Node's output files with transfer flag as true have locations recorded in the Replica Catalog
)
)
)
By default, the Pegasus Workflow Planner registers outputs marked for registration in the abstract workflow, in an output replica catalog in the workflow submit directory. You can use –reuse option to pegasus-plan to pass a list of submit directories, whose output replica catalogs you want to use for data reuse for your current run.
Tip
The Data Reuse Algorithm can be disabled by passing the –force option to pegasus-plan.
You can pass –reuse option to pegasus-plan to pass a list of submit directories of your previous runs to automatically pick up locations of outputs registered in those runs.
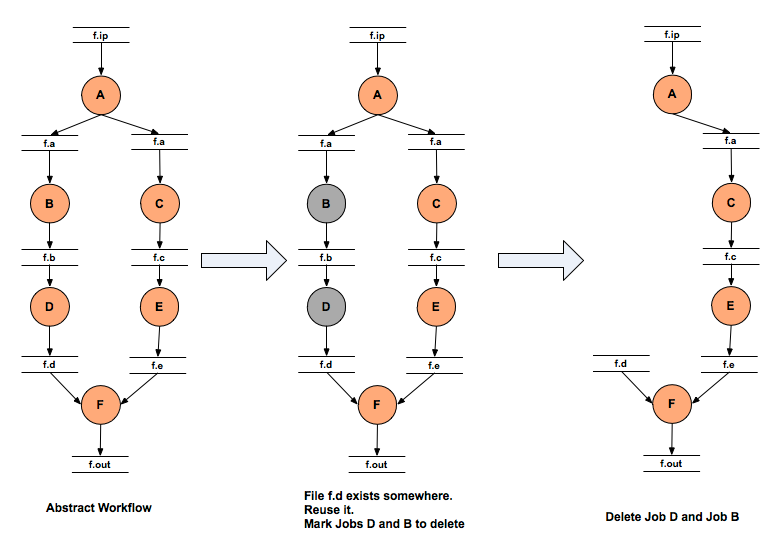
Workflow Data Reuse
4.2. Site Selection
The abstract workflow is then handed over to the Site Selector module where the abstract jobs in the pruned workflow are mapped to the various sites passed by a user. The target sites for planning are specified on the command line using the–sites option to pegasus-plan. If not specified, then Pegasus picks up all the sites in the Site Catalog as candidate sites. Pegasus will map a compute job to a site only if Pegasus can
find an INSTALLED executable on the site
OR find a STAGEABLE executable that can be staged to the site as part of the workflow execution.
Pegasus supports variety of site selectors with Random being the default
Random
The jobs will be randomly distributed among the sites that can execute them.
RoundRobin
The jobs will be assigned in a round robin manner amongst the sites that can execute them. Since each site cannot execute every type of job, the round robin scheduling is done per level on a sorted list. The sorting is on the basis of the number of jobs a particular site has been assigned in that level so far. If a job cannot be run on the first site in the queue (due to no matching entry in the transformation catalog for the transformation referred to by the job), it goes to the next one and so on. This implementation defaults to classic round robin in the case where all the jobs in the workflow can run on all the sites.
Group
Group of jobs will be assigned to the same site that can execute them. The use of thePEGASUS profile key group in the DAX, associates a job with a particular group. The jobs that do not have the profile key associated with them, will be put in the default group. The jobs in the default group are handed over to the “Random” Site Selector for scheduling.
Heft
A version of the HEFT processor scheduling algorithm is used to schedule jobs in the workflow to multiple grid sites. The implementation assumes default data communication costs when jobs are not scheduled on to the same site. Later on this may be made more configurable.
The runtime for the jobs is specified in the transformation catalog by associating the pegasus profile key runtime with the entries.
The number of processors in a site is picked up from the attribute idle-nodes associated with the vanilla jobmanager of the site in the site catalog.
NonJavaCallout
Pegasus will callout to an external site selector.In this mode a temporary file is prepared containing the job information that is passed to the site selector as an argument while invoking it. The path to the site selector is specified by setting the property pegasus.site.selector.path. The environment variables that need to be set to run the site selector can be specified using the properties with a pegasus.site.selector.env. prefix. The temporary file contains information about the job that needs to be scheduled. It contains key value pairs with each key value pair being on a new line and separated by a =.
The following pairs are currently generated for the site selector temporary file that is generated in the NonJavaCallout.
Key Value Pairs that are currently generated for the site selector temporary file that is generated in the NonJavaCallout. Key
Value
version
is the version of the site selector api,currently 2.0.
transformation
is the fully-qualified definition identifier for the transformation (TR) namespace::name:version.
derivation
is the fully qualified definition identifier for the derivation (DV), namespace::name:version.
job.level
is the job’s depth in the tree of the workflow DAG.
job.id
is the job’s ID, as used in the DAX file.
resource.id
is a pool handle, followed by whitespace, followed by a gridftp server. Typically, each gridftp server is enumerated once, so you may have multiple occurances of the same site. There can be multiple occurances of this key.
input.lfn
is an input LFN, optionally followed by a whitespace and file size. There can be multiple occurances of this key,one for each input LFN required by the job.
wf.name
label of the dax, as found in the DAX’s root element. wf.index is the DAX index, that is incremented for each partition in case of deferred planning.
wf.time
is the mtime of the workflow.
wf.manager
is the name of the workflow manager being used .e.g condor
vo.name
is the name of the virtual organization that is running this workflow. It is currently set to NONE
vo.group
unused at present and is set to NONE.
Tip
The site selector to use for site selection can be specified by setting the property pegasus.selector.site
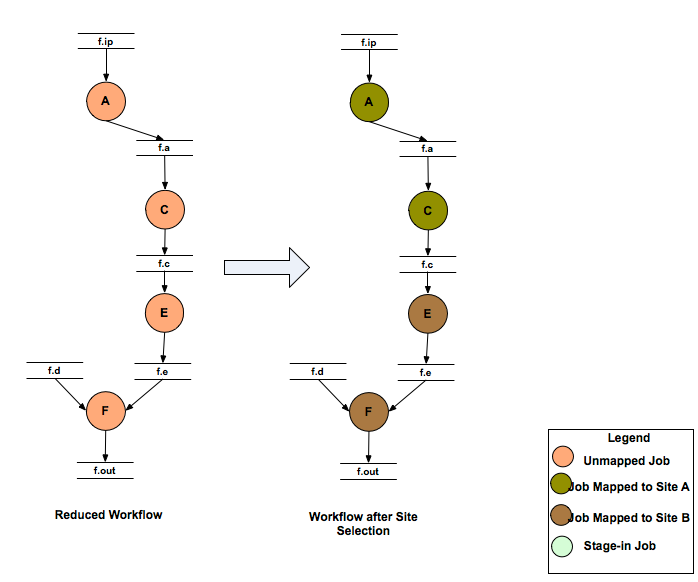
Workflow Site Selection
4.3. Job Clustering
After site selection, the workflow is optionally handed for to the job clustering module, which clusters jobs that are scheduled to the same site. Clustering is usually done on short running jobs in order to reduce the remote execution overheads associated with a job. Clustering is described in detail in the optimization chapter.
Tip
The job clustering is turned on by passing the –cluster option to pegasus-plan.
4.4. Addition of Data Transfer and Registration Nodes
After job clustering, the workflow is handed to the Data Transfer module that adds data stage-in , inter site and stage-out nodes to the workflow. Data Stage-in Nodes transfer input data required by the workflow from the locations specified in the Replica Catalog to a directory on the staging site associated with the job. The staging site for a job is the execution site if running in a sharedfs mode, else it is the one specified by –staging-site option to the planner. In case, multiple locations are specified for the same input file, the location from where to stage the data is selected using a Replica Selector . Replica Selection is described in detail in the Replica Selection section of the Data Management chapter. More details about staging site can be found in the data staging configuration section.
The process of adding the data stage-in and data stage-out nodes is handled by Transfer Refiners. All data transfer jobs in Pegasus are executed using pegasus-transfer . The pegasus-transfer client is a python based wrapper around various transfer clients like globus-url-copy, s3cmd, irods-transfer, scp, wget, cp, ln . It looks at source and destination url and figures out automatically which underlying client to use. pegasus-transfer is distributed with the PEGASUS and can be found in the bin subdirectory . Pegasus Transfer Refiners are are described in the detail in the Transfers section of the Data Management chapter. The default transfer refiner that is used in Pegasus is the BalancedCluster Transfer Refiner, that clusters data stage-in nodes and data stage-out nodes per level of the workflow, on the basis of certain pegasus profile keys associated with the workflow.
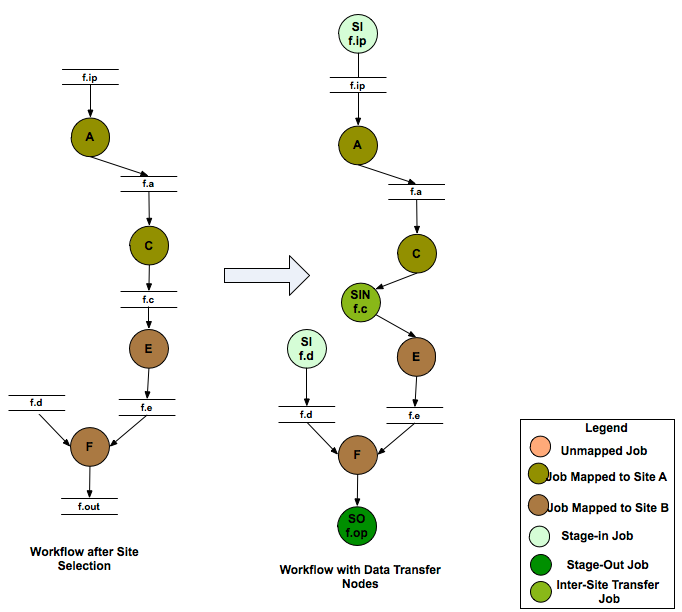
Addition of Data Transfer Nodes to the Workflow
Data Registration Nodes may also be added to the final executable workflow to register the location of the output files on the final output site back in the Replica Catalog . An output file is registered in the Replica Catalog if the register flag for the file is set to true in the DAX.
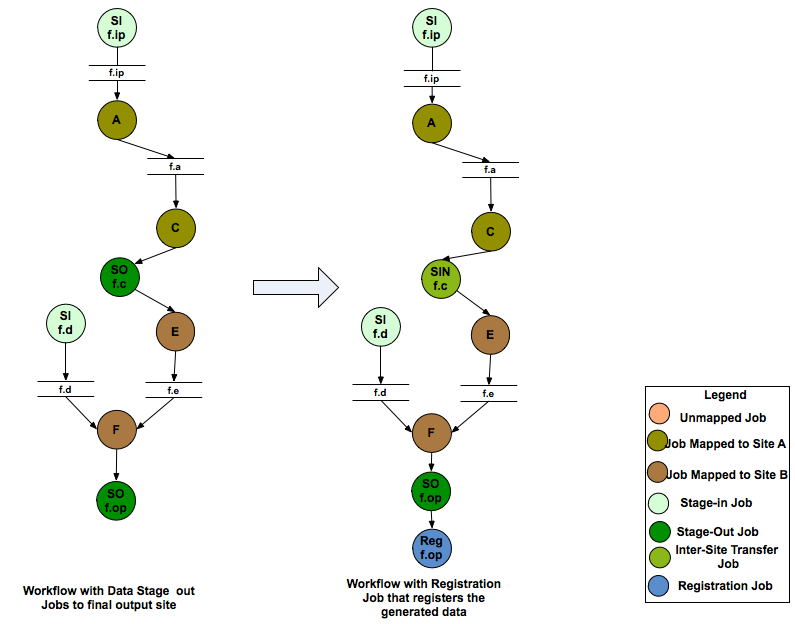
Addition of Data Registration Nodes to the Workflow
The data staged-in and staged-out from a directory that is created on the head node by a create dir job in the workflow. In the vanilla case, the directory is visible to all the worker nodes and compute jobs are launched in this directory on the shared filesystem. In the case where there is no shared filesystem, users can turn on worker node execution, where the data is staged from the head node directory to a directory on the worker node filesystem. This feature will be refined further for Pegasus 3.1. To use it with Pegasus 3.0 send email to pegasus-support at isi.edu.
Tip
The replica selector to use for replica selection can be specified by setting the property pegasus.selector.replica
4.5. Addition of Create Dir and Cleanup Jobs
After the data transfer nodes have been added to the workflow, Pegasus adds a create dir jobs to the workflow. Pegasus usually , creates one workflow specific directory per compute site , that is on the staging site associated with the job. In the case of shared shared filesystem setup, it is a directory on the shared filesystem of the compute site. In case of shared filesystem setup, this directory is visible to all the worker nodes and that is where the data is staged-in by the data stage-in jobs.
The staging site for a job is the execution site if running in a sharedfs mode, else it is the one specified by –staging-site option to the planner. More details about staging site can be found in the data staging configuration chapter.
After addition of the create dir jobs, the workflow is optionally handed to the cleanup module. The cleanup module adds cleanup nodes to the workflow that remove data from the directory on the shared filesystem when it is no longer required by the workflow. This is useful in reducing the peak storage requirements of the workflow.
Tip
The addition of the cleanup nodes to the workflow can be disabled by passing the –nocleanup option to pegasus-plan.
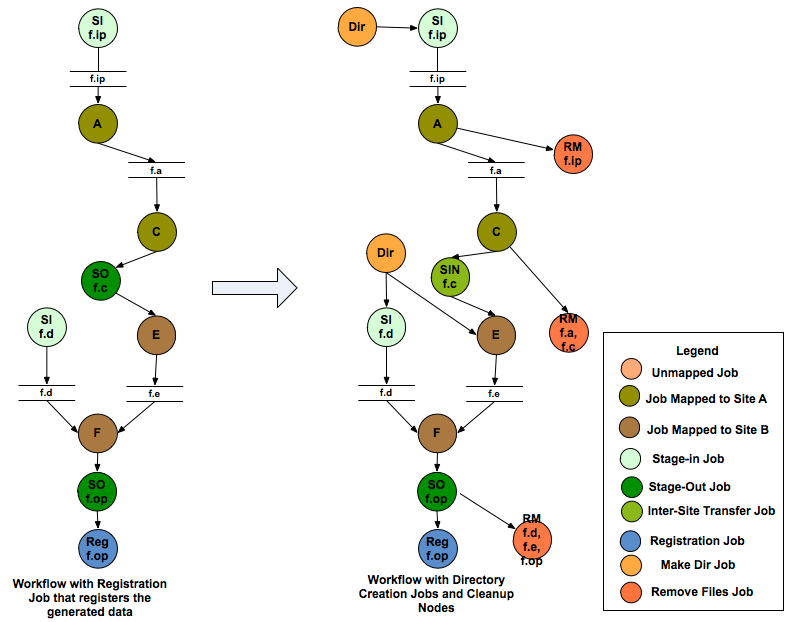
Addition of Directory Creation and File Removal Jobs
Tip
Users can specify the maximum number of cleanup jobs added per level by specifying the property pegasus.file.cleanup.clusters.num in the properties.
4.6. Code Generation
The last step of refinement process, is the code generation where Pegasus writes out the executable workflow in a form understandable by the underlying workflow executor. At present Pegasus supports the following code generators
Condor
This is the default code generator for Pegasus . This generator generates the executable workflow as a Condor DAG file and associated job submit files. The Condor DAG file is passed as input to Condor DAGMan for job execution.
Shell
This Code Generator generates the executable workflow as a shell script that can be executed on the submit host. While using this code generator, all the jobs should be mapped to site local i.e specify –sites local to pegasus-plan.
Tip
To use the Shell code Generator set the property pegasus.code.generator Shell
PMC
This Code Generator generates the executable workflow as a PMC task workflow. This is useful to run on platforms where it not feasible to run Condor such as the new XSEDE machines such as Blue Waters. In this mode, Pegasus will generate the executable workflow as a PMC task workflow and a sample PBS submit script that submits this workflow. Note that the generated PBS file needs to be manually updated before it can be submitted.
Tip
To use the Shell code Generator set the property pegasus.code.generator PMC
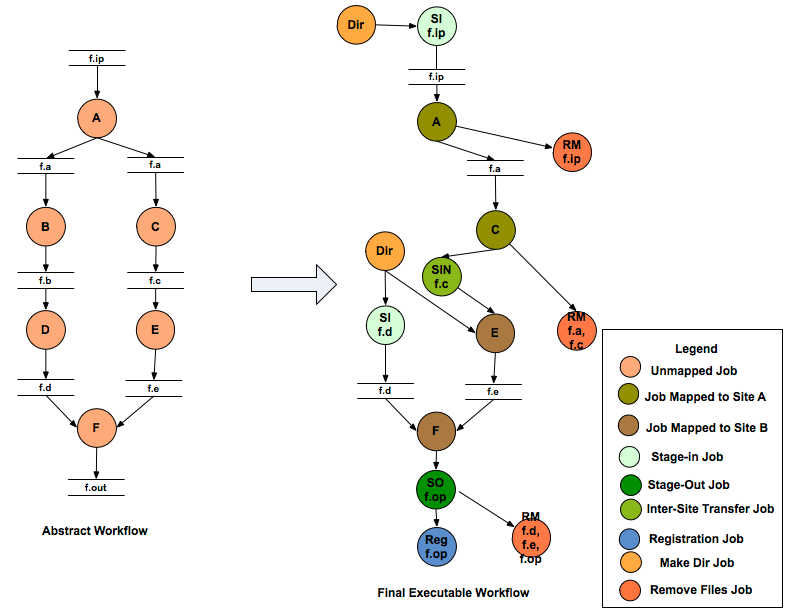
Final Executable Workflow