7. PegasusLite
Starting Pegasus 4.0 , all compute jobs ( single or clustered jobs) that are executed in a non shared filesystem setup, are executed using lightweight job wrapper called PegasusLite.
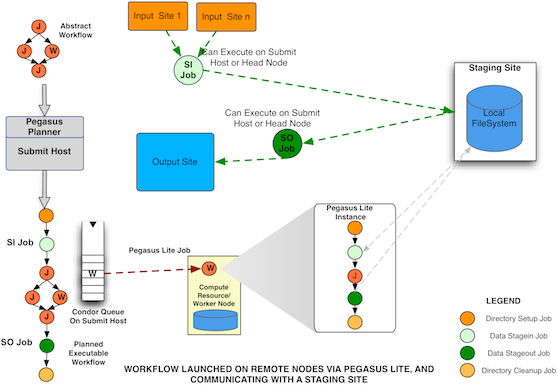
Workflow Running in NonShared Filesystem Setup with PegasusLite launching compute jobs
When PegasusLite starts on a remote worker node to run a compute job , it performs the following actions:
Discovers the best run-time directory based on space requirements and create the directory on the local filesystem of the worker node to execute the job.
Prepare the node for executing the unit of work. This involves discovering whether the pegasus worker tools are already installed on the node or need to be brought in.
Use pegasus-transfer to stage in the input data to the runtime directory (created in step 1) on the remote worker node.
If enabled, do integrity checking on the input files transferred to the remote worker node. This is done by computing a new checksum on the file staged and matching it with the one in the job description.
Launch the compute job.
Use pegasus-transfer to stage out the output data to the data coordination site.
Remove the directory created in Step 1.
Note
If you are using containers for your workflow, then Steps 3-6 will occur inside the container dependant on how transfers for containers are configured.
Below is a sequence diagram that illustrates how a job in an abstract workflow after being mapped to an executable workflow, gets executed on a remote slurm cluster using PegasusLite
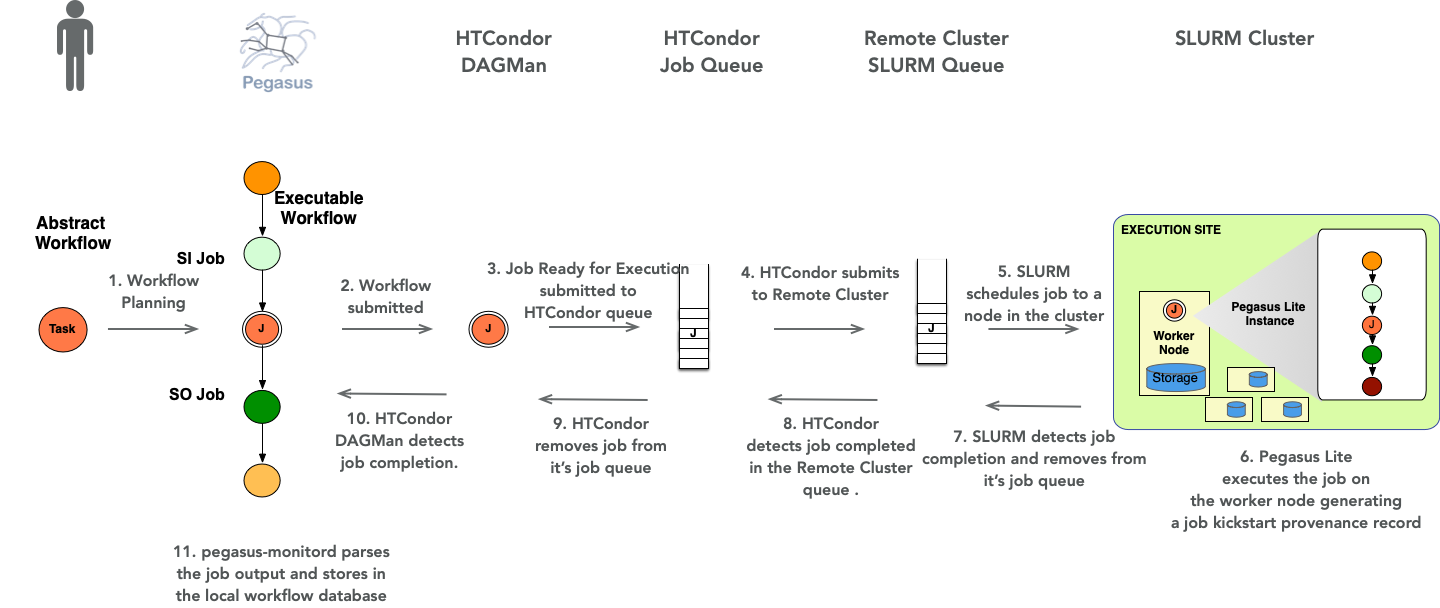
Job Sequence for a job executed via PegasusLite
7.1. Setting the directory on the local filesystem for the job
By default, PegasusLite discovers the best run-time directory based on space requirements and creates the directory on the local filesystem of the worker node to execute the job. If you want to specify a particular directory where job should run in via PegasusLite you can
specify in the Site Catalog for the compute site where the PegasusLite job will run, a Directory of type LOCAL_SCRATCH . This internally, ensures that in the generated PegasusLite script PEGASUS_WN_TMP environment variable is set to the localScratch directory specified. For example
from Pegasus.api import * shared_scratch_dir = "/shared/scratch") local_scratch_dir = "/local/scratch") compute = Site("compute").add_directories( Directory( Directory.SHARED_SCRATCH, shared_scratch_dir, shared_file_system=True ).add_file_servers(FileServer("file://" + shared_scratch_dir, Operation.ALL)), Directory(Directory.LOCAL_SCRATCH, local_scratch_dir).add_file_servers( FileServer("file://" + local_scratch_dir, Operation.ALL) ), )
pegasus: '5.0' sites: - name: compute directories: - type: sharedScratch path: /shared/scratch sharedFileSystem: true fileServers: - url: file:///shared/scratch" operation: all - type: localScratch path: /local/scratch sharedFileSystem: false fileServers: - url: file:///local/scratch operation: all
7.2. Setting the environment in PegasusLite for your job
In addition, to the usual environment profiles that you can associate with your job in the various catalogs, PegasusLite allows you to specify a user provided environment setup script file that is sourced early in the generated PegasusLite wrapper. The purpose of this is to allow users to specify to do things such as module load to load appropriate libraries required by their jobs; when they run on nodes on a cluster.
In order to specify this setup script, you can specify it in the Site Catalog in the following ways. Priority order listed below is highest to lowest.
Pegasus profile named pegasus_lite_env_source associated with site where the job runs, that indicates a path to a setup script residing on the submit host that needs to be sourced in PegasusLite when running the job. This file is then transferred using Condor file transfer from the submit host to the compute node where the job executes.
Pegasus profile named pegasus_lite_env_source associated with site local that indicates a path to a setup script residing on the submit host that needs to be sourced in PegasusLite when running the job. This file is then transferred using Condor file transfer from the submit host to the compute node where the job executes.
If the setup script already is present on the compute nodes on the cluster; path to it can be set as an env profile named PEGASUS_LITE_ENV_SOURCE with the compute site.
7.3. Specify Compute Job in PegasusLite to run on different node
When running workflows on systems such as OLCF summit, data staging can be tricky for PegasusLite jobs. The data staging needs to happen on the cluster Service nodes, while the compute job need to be launched using the jsrun command to execute on the compute nodes.
For example; an invocation of a compute job in PegasusLite would need to look like this
jsrun -n 1 -a 1 -c 42 -g 0 /path/to/kickstart user-executable args
The above cannot be achieved by specifying a job wrapper, as mentioning the wrapper as the executable path in TC, as in that case pegasus-kickstart will run on the Service node, and invoke the jsrun command.
To get this behavior you can specify the following Pegasus Profile keys with your job
gridstart.launcher : Specifies the launcher executable to use to launch the GridStart(pegasus-kickstart). In the above example value for this would be jsrun.
gridstart.launcher.arguments: Specifies the arguments to pass to the launcher. In the above example, value for this would be -n 1 -a 1 -c 42 -g 0 .
7.4. Specify Wrapper to Launch a Containerized Compute Job in PegasusLite
When running workflows with containerized jobs such as Tensor Flow, PyTorch or even Open MPI jobs via PegasusLite, one may encounter a situation where the actual docker or singularity invocation has to be prefixed with srun for example, to allow for a job to detect and use the multiple cores on a node.
For example; an invocation of a containerized compute job in PegasusLite would need to look like this
srun –kill-on-bad-exit $singularity_exec exec –no-home –bind $PWD:/srv –bind /scratch image.sif /srv/job-cont.sh
The above cannot be achieved by specifying a gridstart launcher, as mentioning the launcher for the job will wrap pegasus-kickstart invocation that happens inside the container as part of the /srv/job-cont.sh. In this scenario, we want the wrapper (srun) to run on the HOST OS.
To get this behavior you can specify the following Pegasus Profile keys with your job
container.launcher : Specifies the launcher executable to use to launch the singularity|docker invocation. In the above example value for this would be srun.
container.launcher.arguments: Specifies the arguments to pass to the launcher. In the above example, value for this would be –kill-on-bad-exit .