11. Data Transfers
As part of the Workflow Mapping Process, Pegasus does data management for the executable workflow . It queries a Replica Catalog to discover the locations of the input datasets and adds data movement and registration nodes in the workflow to:
Stage-in input data to the staging sites (a site associated with the compute job to be used for staging. In the shared filesystem setup, staging site is the same as the execution sites where the jobs in the workflow are executed).
Stage-out output data generated by the workflow to the final storage sites.
Stage-in intermediate data between compute sites if required.
Data registration nodes to catalog the locations of the output data on the final storage sites into the replica catalog.
The separate data movement jobs that are added to the executable workflow are responsible for staging data to a workflow specific directory accessible to the staging server on a staging site associated with the compute sites. Depending on the data staging configuration, the staging site for a compute site is the compute site itself. In the default case, the staging server is usually on the headnode of the compute site and has access to the shared filesystem between the worker nodes and the head node. Pegasus adds a directory creation job in the executable workflow that creates the workflow specific directory on the staging server.
In addition to data, Pegasus will transfer user executables to the compute sites if the executables are not installed on the remote sites before hand. This chapter gives an overview of how the transfers of data and executables are managed in Pegasus.
Pegasus picks up files for data transfers based on the transfer attribute associated with the input and output files for the job. These are designated in the Abstract Workflow as uses elements in the job element. If not specified, the transfer flag defaults to true. So if you don’t want all the generated files to be transferred to the output sites, you need to explicitly set the stage_out flag to false for the file.
#! /usr/bin/env python3
import logging
from pathlib import Path
from Pegasus.api import *
..
# --- Raw input file -----------------------------------------------------------------
fa = File("f.a").add_metadata(creator="ryan")
fb1 = File("f.b1")
fb2 = File("f.b2")
# fb2 output is explicitly disabled by setting the stage_out flag
job_preprocess = Job("preprocess")\
.add_args("-a", "preprocess", "-T", "3", "-i", fa, "-o", fb1, fb2)\
.add_inputs(fa)\
.add_outputs(fb1)\
.add_outputs(fb1, stage_out=False)
- type: job
name: preprocess
id: ID0000001
arguments: [-a, preprocess, -T, "3", -i, f.a, -o, f.b1, f.b2]
uses:
- lfn: f.a
type: input
- lfn: f.b1
type: output
stageOut: true
registerReplica: true
- lfn: f.b2
type: output
stageOut: false
registerReplica: true
11.1. Data Staging Configuration
Pegasus can be broadly setup to run workflows in the following configurations:
Condor Pool Without a shared filesystem
This setup applies to a condor pool where the worker nodes making up a condor pool don’t share a filesystem. All data IO is achieved using Condor File IO. This is a special case of the non shared filesystem setup, where instead of using pegasus-transfer to transfer input and output data, Condor File IO is used. This is the default data staging configuration in Pegasus.
NonShared FileSystem
This setup applies to where the head node and the worker nodes of a cluster don’t share a filesystem. Compute jobs in the workflow run in a local directory on the worker node.
Shared File System
This setup applies to where the head node and the worker nodes of a cluster share a filesystem. Compute jobs in the workflow run in a directory on the shared filesystem.
Note
The default data staging configuration was changed from sharedfs (Shared File System) to condorio (Condor Pool Without a shared filesystem) starting with Pegasus 5.0 release.
For the purposes of data configuration various sites, and directories are defined below.
Submit Host
The host from where the workflows are submitted. This is where Pegasus and Condor DAGMan are installed. This is referred to as the “local” site in the site catalog.
Compute Site
The site where the jobs mentioned in the Abstract Workflow are executed. There needs to be an entry in the Site Catalog for every compute site. The compute site is passed to pegasus-plan using the –sites option.
Staging Site
A site to which the separate transfer jobs in the executable workflow (jobs with stage_in , stage_out and stage_inter prefixes that Pegasus adds using the transfer refiners) stage the input data to and the output data from to transfer to the final output site. Currently, the staging site is always the compute site where the jobs execute.
Output Site
The output site is the final storage site where the users want the output data from jobs to go to. The output site is passed to pegasus-plan using the –output option. The stageout jobs in the workflow stage the data from the staging site to the final storage site.
Input Site
The site where the input data is stored. The locations of the input data are catalogued in the Replica Catalog, and the “site” attribute of the locations gives us the site handle for the input site.
Workflow Execution Directory
This is the directory created by the create dir jobs in the executable workflow on the Staging Site. This is a directory per workflow per staging site. Currently, the Staging site is always the Compute Site.
Worker Node Directory
This is the directory created on the worker nodes per job usually by the job wrapper that launches the job.
11.1.1. Condor Pool Without a Shared Filesystem
By default, Pegasus is setup to do your data transfers in this mode. This setup applies to a condor pool where the worker nodes making up a condor pool don’t share a filesystem. All data IO is achieved using Condor File IO. This is a special case of the non shared filesystem setup, where instead of using pegasus-transfer to transfer input and output data, Condor File IO is used.
Setup
Submit Host and staging site are same.
Head node and worker nodes of compute site don’t share a filesystem.
Input Data is staged from remote sites.
Remote Output Site i.e site other than compute site. Can be submit host.
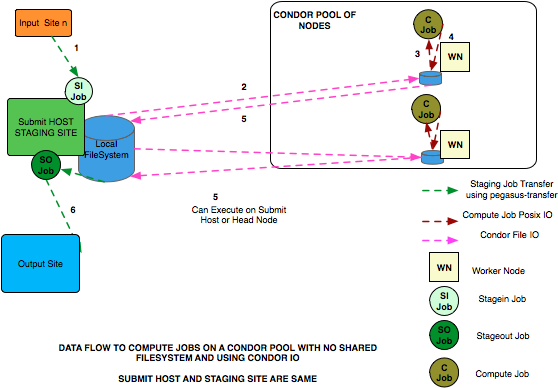
Condor Pool Without a Shared Filesystem
The data flow is as follows in this case:
Stagein Job executes on the submit host to stage in input data from Input Sites (1—n) to a workflow specific execution directory on the submit host.
Compute Job starts on a worker node in a local execution directory. Before the compute job starts, Condor transfers the input data for the job from the workflow execution directory on thesubmit host to the local execution directory on the worker node.
The compute job executes in the worker node, and executes on the worker node.
The compute Job writes out output data to the local directory on the worker node using Posix I/O.
When the compute job finishes, Condor transfers the output data for the job from the local execution directory on the worker node to the workflow execution directory on the submit host.
Stageout Job executes ( either on Submit Host or staging site ) to stage out output data from the workflow specific execution directory to a directory on the final output site.
In this case, the compute jobs are wrapped as PegasusLite instances.
This mode is especially useful for running in the cloud environments where you don’t want to setup a shared filesystem between the worker nodes. Running in that mode is explained in detail here.
Tip
Set pegasus.data.configuration to condorio to run in this configuration. In this mode, the staging site is automatically set to site local
In this setup, Pegasus always stages the input files through the submit host i.e the stage-in job stages in data from the input site to the submit host (local site). The input data is then transferred to remote worker nodes from the submit host using Condor file transfers. In the case, where the input data is locally accessible at the submit host i.e the input site and the submit host are the same, then it is possible to bypass the creation of separate stage in jobs that copy the data to the workflow specific directory on the submit host. Instead, Condor file transfers can be setup to transfer the input files directly from the locally accessible input locations ( file URL’s with “site” attribute set to local) specified in the replica catalog. More details can be found at Bypass Input File Staging.
In some cases, it might be useful to setup the PegasusLite jobs to pull input data directly from the input site without going through the staging server.
11.1.2. Non Shared Filesystem
In this setup , Pegasus runs workflows on local file-systems of worker nodes with the the worker nodes not sharing a filesystem. The data transfers happen between the worker node and a staging / data coordination site. The staging site server can be a file server on the head node of a cluster or can be on a separate machine.
Setup
Compute and staging site are the different.
Head node and worker nodes of compute site don’t share a filesystem.
Input Data is staged from remote sites.
Remote Output Site i.e site other than compute site. Can be submit host.
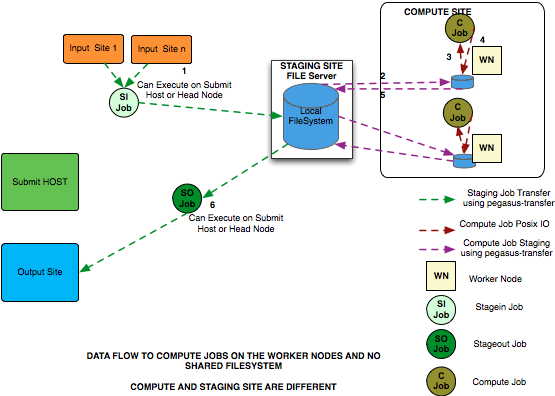
Non Shared Filesystem Setup
The data flow is as follows in this case:
Stagein Job executes (either on Submit Host or on staging site) to stage in input data from Input Sites (1—n) to a workflow specific execution directory on the staging site.
Compute Job starts on a worker node in a local execution directory. Accesses the input data using pegasus transfer to transfer the data from the staging site to a local directory on the worker node.
The compute job executes in the worker node, and executes on the worker node.
The compute Job writes out output data to the local directory on the worker node using Posix I/O.
Output Data is pushed out to the staging site from the worker node using pegasus-transfer.
Stageout Job executes ( either on Submit Host or staging site ) to stage out output data from the workflow specific execution directory to a directory on the final output site.
In this case, the compute jobs are wrapped as PegasusLite instances.
This mode is especially useful for running in the cloud environments where you don’t want to setup a shared filesystem between the worker nodes. Running in that mode is explained in detail here.
Tip
Set pegasus.data.configuration to nonsharedfs to run in this configuration. The staging site can be specified using the –staging-site option to pegasus-plan.
In this setup, Pegasus always stages the input files through the staging site i.e the stage-in job stages in data from the input site to the staging site. The PegasusLite jobs that start up on the worker nodes, then pull the input data from the staging site for each job. In some cases, it might be useful to setup the PegasusLite jobs to pull input data directly from the input site without going through the staging server. More details can be found at Bypass Input File Staging.
11.1.3. Shared File System
In this setup, Pegasus runs workflows in the shared file system setup, where the worker nodes and the head node of a cluster share a filesystem.
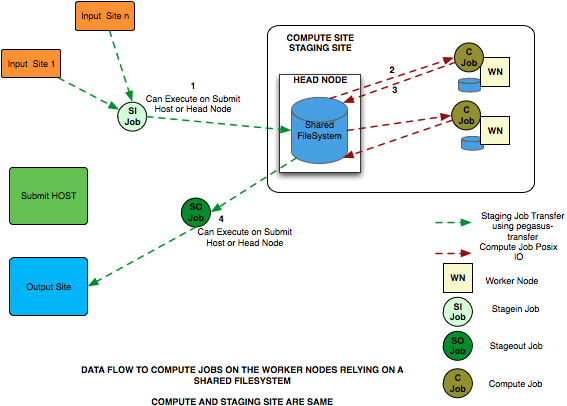
Shared File System Setup
In this setup, the data flow is as follows:
Stagein Job executes ( either on Submit Host or Head Node ) to stage in input data from Input Sites ( 1—n) to a workflow specific execution directory on the shared filesystem.
Compute Job starts on a worker node in the workflow execution directory. Accesses the input data using Posix IO
Compute Job executes on the worker node and writes out output data to workflow execution directory using Posix IO
Stageout Job executes ( either on Submit Host or Head Node ) to stage out output data from the workflow specific execution directory to a directory on the final output site.
Tip
Set pegasus.data.configuration to sharedfs to run in this configuration.
11.2. Local versus Remote Transfers
As far as possible, Pegasus will ensure that the transfer jobs added to the executable workflow are executed on the submit host. By default, Pegasus will schedule a transfer to be executed on the remote staging site only if there is no way to execute it on the submit host. Some scenarios where transfer jobs are executed on remote sites are as follows:
the file server specified for the staging site/compute site is a file server. In that case, Pegasus will schedule all the stage in data movement jobs on the compute site to stage-in the input data for the workflow.
a user has symlinking turned on. In that case, the transfer jobs that symlink against the input data on the compute site, will be executed remotely ( on the compute site ).
In certain execution environments, such a local campus cluster the compute site and the local share a filesystem ( i.e. compute site has file servers specified for the staging/compute site, and the scratch and storage directories mentioned for the compute site are locally mounted on the submit host), it is beneficial to have the remote transfer jobs run locally and hence bypass going through the local scheduler queue. In that case, users can set a boolean profile auxillary.local in pegasus namespace in the site catalog for the compute/staging site to true.
Users can specify the property pegasus.transfer.*.remote.sites to change the default behaviour of Pegasus and force pegasus to run different types of transfer jobs for the sites specified on the remote site. The value of the property is a comma separated list of compute sites for which you want the transfer jobs to run remotely.
The table below illustrates all the possible variations of the property.
Property Name |
Applies to |
|---|---|
pegasus.transfer.stagein.remote.sites |
the stage in transfer jobs |
pegasus.transfer.stageout.remote.sites |
the stage out transfer jobs |
pegasus.transfer.inter.remote.sites |
the inter site transfer jobs |
pegasus.transfer.*.remote.sites |
all types of transfer jobs |
The prefix for the transfer job name indicates whether the transfer job is to be executed locallly ( on the submit host ) or remotely ( on the compute site ). For example stage_in_local_ in a transfer job name stage_in_local_isi_viz_0 indicates that the transfer job is a stage in transfer job that is executed locally and is used to transfer input data to compute site isi_viz. The prefix naming scheme for the transfer jobs is [stage_in|stage_out|inter]_[local|remote]_ .
11.3. Controlling Transfer Parallelism
When it comes to data transfers, Pegasus ships with a default configuration which is trying to strike a balance between performance and aggressiveness. We obviously want data transfers to be as quick as possibly, but we also do not want our transfers to overwhelm data services and systems.
Pegasus adds transfer jobs and cleanup jobs based on the number of jobs at a particular level of the workflow. For example, for every 10 compute jobs on a level of a workflow, one data transfer job( stage-in and stage-out) is created. The default configuration also sets how many threads such a pegasus-transfer job can spawn. Cleanup jobs are similarly constructed with an internal ratio of 5.
Information on how to control the number of stagein and stageout jobs can be found in the Data Movement Nodes section.
To control the number of threads pegasus-transfer can use in standard transfer jobs and when invoked by PegasusLite, see the pegasus.transfer.threads property.
11.4. Symlinking Against Input Data
If input data for a job already exists on a compute site, then it is possible for Pegasus to symlink against that data. In this case, the remote stage in transfer jobs that Pegasus adds to the executable workflow will symlink instead of doing a copy of the data.
Pegasus determines whether a file is on the same site as the compute site, by inspecting the “site” attribute associated with the URL in the Replica Catalog. If the “site” attribute of an input file location matches the compute site where the job is scheduled, then that particular input file is a candidate for symlinking.
For Pegasus to symlink against existing input data on a compute site, following must be true
Property pegasus.transfer.links is set to true
The input file location in the Replica Catalog has the “site” attribute matching the compute site.
Symlinking is NOT turned OFF at a job level by associating a Pegasus profile nosymlink with the job.
Tip
To confirm if a particular input file is symlinked instead of being copied, look for the destination URL for that file in stage_in_remote*.in file. The destination URL will start with symlink:// .
In the symlinking case, Pegasus strips out URL prefix from a URL and replaces it with a file URL.
For example if a user has the following URL catalogued in the Replica Catalog for an input file f.input
f.input gsiftp://server.isi.edu/shared/storage/input/data/f.input site="isi"
and the compute job that requires this file executes on a compute site named isi , then if symlinking is turned on the data stage in job (stage_in_remote_viz_0 ) will have the following source and destination specified for the file
#viz viz
file:///shared/storage/input/data/f.input symlink://shared-scratch/workflow-exec-dir/f.input
11.4.1. Symlinking in Containers
Also when jobs are launched via application containers, Pegasus does support symbolic linking of input data sets from directories visible on the host filesystem. More details can be found here.
11.5. Addition of Separate Data Movement Nodes to Executable Workflow
Pegasus relies on a Transfer Refiner that comes up with the strategy on how many data movement nodes are added to the executable workflow. All the compute jobs scheduled to a site share the same workflow specific directory. The transfer refiners ensure that only one copy of the input data is transferred to the workflow execution directory. This is to prevent data clobbering . Data clobbering can occur when compute jobs of a workflow share some input files, and have different stage in transfer jobs associated with them that are staging the shared files to the same destination workflow execution directory.
Pegasus supports three different transfer refiners that dictate how the stagein and stageout jobs are added for the workflow.The default Transfer Refiner used in Pegasus is the BalancedCluster Refiner. Starting 4.8.0 release, the default configuration of Pegasus now adds transfer jobs and cleanup jobs based on the number of jobs at a particular level of the workflow. For example, for every 10 compute jobs on a level of a workflow, one data transfer job( stage-in and stage-out) is created.
The transfer refiners also allow the user to specify how many local|remote stagein|stageout jobs are created per execution site.
The behavior of the refiners (BalancedCluster and Cluster) are controlled by specifying certain pegasus profiles
either with the execution sites in the site catalog
OR globally in the properties file
Profile Key |
Description |
|---|---|
stagein.clusters |
This key determines the maximum number of stage-in jobs that are can executed locally or remotely per compute site per workflow. |
stagein.local.clusters |
This key provides finer grained control in determining the number of stage-in jobs that are executed locally and are responsible for staging data to a particular remote site. |
stagein.remote.clusters |
This key provides finer grained control in determining the number of stage-in jobs that are executed remotely on the remote site and are responsible for staging data to it. |
stageout.clusters |
This key determines the maximum number of stage-out jobs that are can executed locally or remotely per compute site per workflow. |
stageout.local.clusters |
This key provides finer grained control in determining the number of stage-out jobs that are executed locally and are responsible for staging data from a particular remote site. |
stageout.remote.clusters |
This key provides finer grained control in determining the number of stage-out jobs that are executed remotely on the remote site and are responsible for staging data from it. |
Tip
Which transfer refiner to use is controlled by property pegasus.transfer.refiner
11.5.1. BalancedCluster
This is a new transfer refiner that was introduced in Pegasus 4.4.0 and is the default one used in Pegasus. It does a round robin distribution of the files amongst the stagein and stageout jobs per level of the workflow. The figure below illustrates the behavior of this transfer refiner.
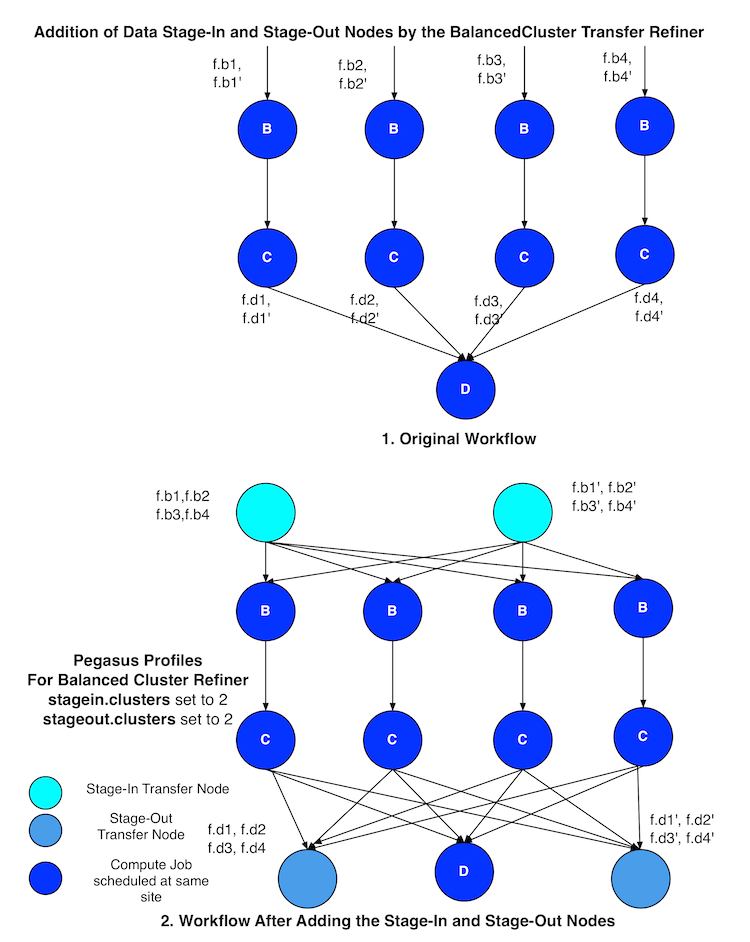
11.5.2. Cluster
This transfer refiner is similar to BalancedCluster but differs in the way how distribution of files happen across stagein and stageout jobs per level of the workflow. In this refiner, all the input files for a job get associated with a single transfer job. As illustrated in the figure below each compute usually gets associated with one stagein transfer job. In contrast, for the BalancedCluster a compute job maybe associated with multiple data stagein jobs.
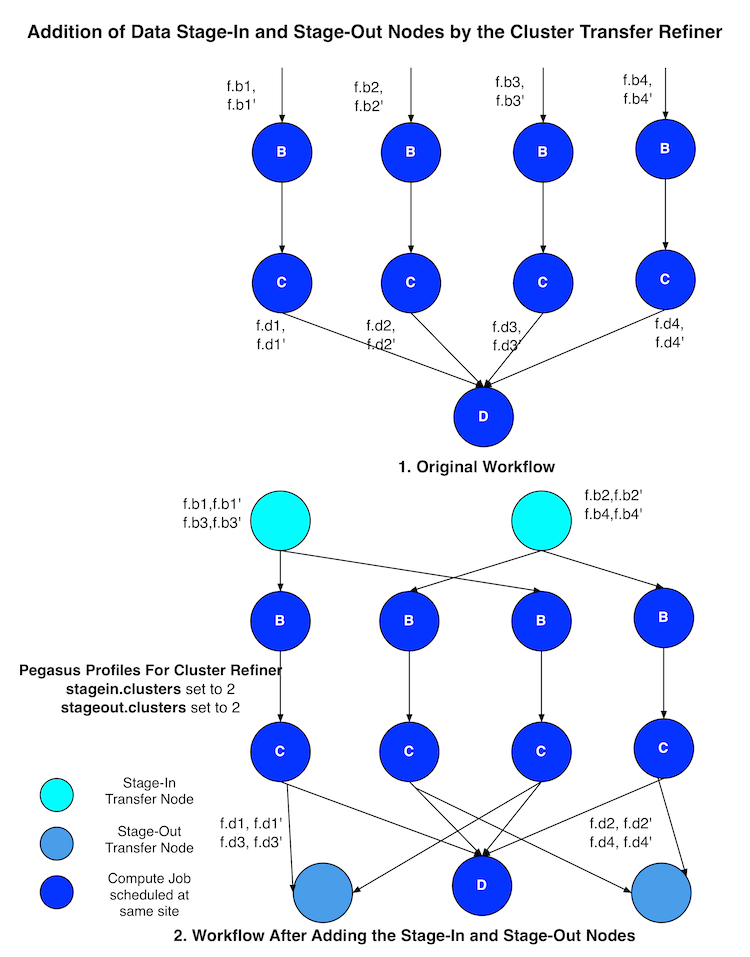
11.5.3. Basic
Pegasus also supports a basic Transfer Refiner that adds one stagein and stageout job per compute job of the workflow. This is not recommended to be used for large workflows as the number of data transfer nodes in the worst case are 2n where n is the number of compute jobs in the workflow.
11.6. Staging of Executables
Users can get Pegasus to stage the user executable ( executable that the jobs in the Abstract Workflow refer to ) as part of the transfer jobs to the workflow specific execution directory on the compute site. The URL locations of the executable need to be specified in the transformation catalog as the PFN and the type of executable needs to be set to STAGEABLE .
The location of a transformation can be specified either in
Abstract Workflow in the executable section. More details here .
Transformation Catalog. More details here .
A particular transformation catalog entry of type STAGEABLE is compatible with a compute site only if all the System Information attributes associated with the entry match with the System Information attributes for the compute site in the Site Catalog. The following attributes make up the System Information attributes
arch
os
osrelease
osversion
11.6.1. Transformation Mappers
Pegasus has a notion of transformation mappers that determines what type of executable are picked up when a job is executed on a remote compute site. For transfer of executable, Pegasus constructs a soft state map that resides on top of the transformation catalog, that helps in determining the locations from where an executable can be staged to the remote site.
Users can specify the following property to pick up a specific transformation mapper
pegasus.catalog.transformation.mapper
Currently, the following transformation mappers are supported.
Transformation Mapper |
Description |
|---|---|
Installed |
This mapper only relies on transformation catalog entries that are of type INSTALLED to construct the soft state map. This results in Pegasus never doing any transfer of executable as part of the workflow. It always prefers the installed executable at the remote sites |
Staged |
This mapper only relies on matching transformation catalog entries that are of type STAGEABLE to construct the soft state map. This results in the executable workflow referring only to the staged executable, irrespective of the fact that the executable are already installed at the remote end |
All |
This mapper relies on all matching transformation catalog entries of type STAGEABLE or INSTALLED for a particular transformation as valid sources for the transfer of executable. This the most general mode, and results in the constructing the map as a result of the cartesian product of the matches. |
Submit |
This mapper only on matching transformation catalog entries that are of type STAGEABLE and reside at the submit host (site local), are used while constructing the soft state map. This is especially helpful, when the user wants to use the latest compute code for his computations on the grid and that relies on his submit host. |
11.7. Staging of Worker Package
The worker package contains runtime tools such as pegasus-kickstart and pegasus-transfer, and is required to be available for most jobs.
How the package is made available to the jobs depends on multiple factors. For example, a pre-installed Pegasus can be used if the location is set using the environment profile PEGASUS_HOME for the site in the Site Catalog.
If Pegasus is not already available on the execution site, the worker package can be staged by setting the following property:
pegasus.transfer.worker.package true
Note that how the package is transferred and accessed differs based on the configured data management mode:
sharedfs mode: the package is staged in to the shared filesystem once, and reused for all the jobs
nonsharedfs or condorio mode: each job carries a worker package. This is obviously less efficient, but the size of the worker package is kept small to minimize the impact of these extra transfers.
Which worker package is used is determined in the following order:
There is an entry for pegasus::worker executable in the transformation catalog. Information on how to construct that entry is provided below.
The planner at runtime creates a worker package out of the binary installation, and puts it in the submit directory. This worker package is used if the OS and architecture of the created worker package match with remote site, or there is an exact match with (osrelease and osversion) if specified by the user in the site catalog for the remote site.
The worker package compatible with the remote site is available as a binary from the Pegasus download site.
At runtime, in the nonsharedfs or condorio modes, extra checks are made to make sure the worker package matches the Pegasus version and the OS and architecture. The reason is that these workflows might be running in an heterogeneous environment, and thus there is no way to know before the job starts what worker package is required. If the runtime check fails, a worker package matching the Pegasus version, OS and architecture will be downloaded from the Pegasus download site. This behavior can be controlled with the pegasus.transfer.worker.package.autodownload and pegasus.transfer.worker.package.strict properties.
If you want to specify a particular worker package to use, you can specify the transformation pegasus::worker in the transformation catalog with:
type set to STAGEABLE
System Information attributes of the transformation catalog entry match the System Information attributes of the compute site.
the PFN specified should be a remote URL that can be pulled to the compute site.
from Pegasus.api import *
...
# example of specifying a worker package in the transformation catalog
pegasus_worker = Transformation(
"worker",
namespace="pegasus",
site="isi",
pfn="https://download.pegasus.isi.edu/pegasus/4.8.0dev/pegasus-worker-4.8.0dev-x86_64_macos_10.tar.gz",
is_stageable=True,
)
# example of specifying a worker package in the transformation catalog
x-pegasus: {apiLang: python, createdBy: vahi, createdOn: '07-23-20T16:43:51Z'}
pegasus: '5.0'
transformations:
- namespace: pegasus
name: worker
sites:
- name: isi
pfn: https://download.pegasus.isi.edu/pegasus/4.8.0dev/pegasus-worker-4.8.0dev-x86_64_macos_10.tar.gz
type: stageable
# example of specifying a worker package in the transformation catalog
tr pegasus::worker {
site isi {
pfn "https://download.pegasus.isi.edu/pegasus/4.8.0dev/pegasus-worker-4.8.0dev-x86_64_macos_10.tar.gz"
arch "x86_64"
os "MACOSX"
type "STAGEABLE"
}
}
11.8. Staging of Worker Package into Containers
When a job runs in an application container, the job encounter two (potentially incompatible) OS’es. The first one is the HOST OS where the job get launched by the resource manager (such as SLURM etc.) The other is the OS in the container, in which the job is set to run. Normally, by default PegasusLite scripts at runtime (both on the HOST OS and in the Container OS) will automatically, download an appropriate worker pacakge for the platform. However in some cases, you might want to disable this behavior. Some examples are below
The worker nodes where the job runs do not have access to the internet
The Pegasus Website is down
You want to optimize and not download packages for each job from the Pegasus website.
In this case, worker package staging functionality can be of help. However, worker package staging in Pegasus allows you to specify a worker package for a site in the Site Catalog, and not explicitly for a container. In general, for most of linux flavors, the same worker package should work on the host OS and container OS. If you are using similar flavors of linux, the following settings in your properties can help you turn off downloads of worker package from the Pegasus website, and instead use the worker package specified in the Transformation Catalog.
pegasus.transfer.worker.package=true
pegasus.transfer.worker.package.autodownload=false
Note
In the script that gets invoked in the application container to launch a job, the strict checking of worker package versions is always disabled.
11.9. Staging of Job Checkpoint Files
Pegasus has support for transferring job checkpoint files back to the staging site when a job exceeds its advertised running time or fails due to some error. This can be done by marking file(s) as checkpoint(s) using one of the workflow APIs. The following describes how to do this, using the Python API.
job = Job(exe)\
.add_checkpoint(File("saved_state_a.txt"))\
.add_checkpoint(File("saved_state_b.txt"))
Here we have marked two files, saved_state_a.txt and saved_state_b.txt
as checkpoint files. This means that Pegasus will expect those two files to be
present when the job completes or fails. When the job is restarted (possibly on
a different site), the two checkpoint files will be sent to that site to be
consumed by the job.
Next, we discuss how to address several common application checkpointing scenarios:
You would like Pegasus to signal your application to start writing out a checkpoint file. In this scenario we use the Pegasus profile,
checkpoint.time, to specify the time (in minutes) at which aSIGTERMis to be sent bypegsaus-kickstartto the running executable. The executable should then handle theSIGTERMby starting to write out a checkpoint file. At time(checkpoint.time + (maxwalltime-checkpoint.time)/2), aKILLsignal will be sent to the job. The given formula is used to allow the application time to write the checkpoint file before being sending aSIGKILL.
# SIGTERM will be sent at time = 1 minute
# KILL will be sent at time = (1 + (2 - 1)/2) = 1.5 minutes
job = Job(exe)\
.add_checkpoint(File("saved_state.txt"))\
.add_profiles(Namespace.PEGASUS, key="checkpoint.time", value=1)\
.add_profiles(Namespace.PEGASUS, key="maxwalltime", value=2)
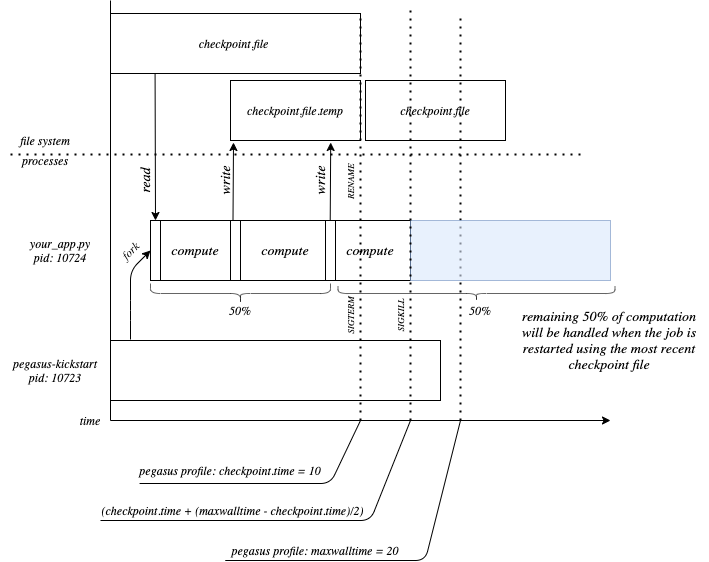
What pegasus-kickstart will do based on
the profiles checkpoint.time and maxwalltime, and how your application
should respond.
The application is expected to run for a very long time and you would like to periodically save checkpoint files. Pegasus currently does not provide the means to asynchrounsly send checkpoint files back to the staging site while a job is running. As such, if your job is expected to run for a very long time (e.g. training a model), you can periodically save checkpoint files by intentionally killing the job and restarting it. To do this, follow the steps outlined above, and ensure that the Pegasus property
dagman.retryis set to some value high enough to allow your application to run to completion. Another way to intentionlly kill the job is to have it write out a checkpoint file, then return nonzero if it is not complete, at which point it will be restarted automatically by Pegasus.
Note
When using the condorio data staging configuration, an empty checkpoint
file (placeholder) must be created and referenced in the replica catalog prior to submitting
the workflow.
Caution
dagman.retryshould be large enough to allow the job to run until completionmaxwalltimeshould be large enough to allow the job to write a checkpoint filemaxwalltimeandcheckpoint.timeshould always be set together; maxwalltime alone will not cause your job to be killed after maxwalltime number of minutes
11.10. Bypass Input File Staging
When executing a workflow in PegasusLite mode (i.e the data configuration is either condorio (default) or bypass), then it is possible to bypass the placement of the raw input data required by the workflow on to the staging site. Instead the PegasusLite wrapped compute jobs, can directly pull the data from the locations specified in the replica catalog. This is based on the assumption that the worker nodes can access the input site. However, you should be aware that the access to the input site is no longer throttled ( as in case of stage in jobs). If large number of compute jobs start at the same time in a workflow, the input server will see a connection from each job.
To enable this you can either
Set the property pegasus.transfer.bypass.input.staging to true to enable bypass of all input files.
OR
You can associate the bypass flag at a per file(data file, executable or container) basis while constructing your workflow using the Python API. Below is a snippet of a generated abstract workflow that highlights bypass at a per file level:
tc = TransformationCatalog() # A container that will be used to execute the following transformations. tools_container = Container( "osgvo-el7", Container.SINGULARITY, image="gsiftp://bamboo.isi.edu/lfs1/bamboo-tests/data/osgvo-el7.img", checksum={"sha256": "dd78aaa88e1c6a8bf31c052eacfa03fba616ebfd903d7b2eb1b0ed6853b48713"}, bypass_staging=True ) tc.add_containers(tools_container) preprocess = Transformation("preprocess", namespace="pegasus", version="4.0").add_sites( TransformationSite( CONDOR_POOL, PEGASUS_LOCATION, is_stageable=True, arch=Arch.X86_64, os_type=OS.LINUX, bypass_staging=True, container=tools_container ) ) print("Generating workflow") fb1 = File("f.b1") fb2 = File("f.b2") fc1 = File("f.c1") fc2 = File("f.c2") fd = File("f.d") try: Workflow("blackdiamond").add_jobs( Job(preprocess) .add_args("-a", "preprocess", "-T", "60", "-i", fa, "-o", fb1, fb2) .add_inputs(fa, bypass_staging=True) .add_outputs(fb1, fb2, register_replica=True))
transformationCatalog: transformations: - namespace: pegasus name: preprocess version: '4.0' sites: - {name: condorpool, pfn: /usr/bin/pegasus-keg, type: stageable, bypass: true, arch: x86_64, os.type: linux, container: osgvo-el7} containers: - name: osgvo-el7 type: singularity image: gsiftp://bamboo.isi.edu/lfs1/bamboo-tests/data/osgvo-el7.img bypass: true checksum: {sha256: dd78aaa88e1c6a8bf31c052eacfa03fba616ebfd903d7b2eb1b0ed6853b48713} jobs: - type: job namespace: pegasus version: '4.0' name: preprocess id: ID0000001 arguments: [-a, preprocess, -T, '60', -i, f.a, -o, f.b1, f.b2] uses: - {lfn: f.b2, type: output, stageOut: true, registerReplica: true} - {lfn: f.a, type: input, bypass: true} - {lfn: f.b1, type: output, stageOut: true, registerReplica: true}
11.10.1. Bypass in condorio mode
In case of condorio data configuration where condor file transfers are used to transfer the input files directly from the locally accessible input locations, you must ensure that file URL’s with “site” attribute set to local are specified in the replica catalog.
Pegasus use of HTCondor File Transfers does not allow for the destination file to have a name that differs from the basename of the file url in the replica catalog. As a result, if the lfn for the input file does not match the basename of the file location specified in the Replica Catalog for that LFN, Pegasus will automatically disable bypass for that file even if it is marked for bypass.
11.10.2. Source URL’s consideration
In addition to setting explicitly what files need to be bypassed, Pegasus also does take into consideration the source URL location of the file, to determine whether the file can be actually bypassed (retrieved directly). If the source URL is a non file URL, then Pegasus does consider it to be a remotely accessible URL and hence allowable to be pulled directly for the job.
For source URL’s that are file URL’s bypass only works if the * site attribute associated with the URL is the same as the compute site. OR
the file URL is at site “local” and the pegasus profile auxillary.local is set to true for the compute site in the site catalog.