6. Monitoring
6.1. Monitoring Database
Pegasus launches a monitoring daemon called pegasus-monitord per
workflow (a single daemon is launched if a user submits a hierarchical
workflow). pegasus-monitord parses the workflow and job logs in the
submit directory and populates to a database. This section gives an
overview of the pegasus-monitord and describes the schema of the runtime
database.
6.1.1. pegasus-monitord
pegasus-monitord is used to follow workflows, parsing the output of
DAGMan’s dagman.out file. In addition to generating the jobstate.log
file, which contains the various states that a job goes through during
the workflow execution, pegasus-monitord can also be used to mine
information from jobs’ submit and output files, and either populate a
database, or write a file with NetLogger events containing this
information. pegasus-monitord can also send notifications to users
in real-time as it parses the workflow execution logs.
pegasus-monitord is automatically invoked by pegasus-run, and
tracks workflows in real-time. By default, it produces the jobstate.log
file, and a SQLite database, which contains all the information listed
in the Stampede schema. When a workflow
fails, and is re-submitted with a rescue DAG, pegasus-monitord will
automatically pick up from where it left previously and continue to
write the jobstate.log file and populate the database.
If, once the workflow has completed, users need to re-create the
jobstate.log file, or re-populate the database from scratch,
pegasus-monitord’s --replay (or -r) option should be used
when running it manually.
6.1.1.1. Populating to different backend databases
In addition to SQLite, pegasus-monitord supports other types of
databases, such as MySQL and Postgres. Users will need to install the
low-level database drivers, and can use the --dest command-line
option, or the pegasus.monitord.output property to select where the
logs should go.
As an example, the command:
$ pegasus-monitord -r diamond-0.dag.dagman.out
will launch pegasus-monitord in replay mode. In this case, if a
jobstate.log file already exists, it will be rotated and a new file will
be created. It will also create/use a SQLite database in the workflow’s
run directory, with the name of diamond-0.stampede.db. If the database
already exists, it will make sure to remove any references to the
current workflow before it populates the database. In this case,
pegasus-monitord will process the workflow information from start to
finish, including any restarts that may have happened.
Users can specify an alternative database for the events, as illustrated by the following examples:
$ pegasus-monitord -r -d mysql://username:userpass@hostname/database_name diamond-0.dag.dagman.out
$ pegasus-monitord -r -d sqlite:////tmp/diamond-0.db diamond-0.dag.dagman.out
In the first example, pegasus-monitord will send the data to the
database_name database located at server hostname, using the
username and userpass provided. In the second example,
pegasus-monitord will store the data in the /tmp/diamond-0.db
SQLite database.
Note
For absolute paths, four slashes are required when specifying an alternative database path in SQLite.
Users should also be aware that in all cases, with the exception of
SQLite, the database should exist before pegasus-monitord is run (as
it creates all needed tables but does not create the database itself).
Finally, the following example:
$ pegasus-monitord -r --dest diamond-0.bp diamond-0.dag.dagman.out
sends events to the diamond-0.bp file. (please note that in replay mode,
any data on the file will be overwritten).
One important detail is that while processing a workflow,
pegasus-monitord will automatically detect if/when sub-workflows are
initiated, and will automatically track those sub-workflows as well. In
this case, although pegasus-monitord will create a separate
jobstate.log file in each workflow directory, the database at the
top-level workflow will contain the information from not only the main
workflow, but also from all sub-workflows.
6.1.1.3. Multiple End points
`pegasus-monitord can be used to publish events
to different backends at the same time. The configuration of this is
managed through properties matching
pegasus.catalog.workflow.<variable-name>.url.
For example, to enable populating to an AMQP end point and a file format in addition to default SQLite you can configure as follows:
pegasus.catalog.workflow.amqp.url amqp://vahi:XXXXX@amqp.isi.edu:5672/panorama/monitoring
pegasus.catalog.workflow.file.url file:///lfs1/work/monitord/amqp/nl.bp
If you want to only override the default SQLite population, then you
can specify the pegasus.catalog.workflow.url property.
6.1.2. Overview of the Workflow Database Schema.
Pegasus takes in an abstract workflow, which is composed of tasks. Pegasus plans it into a Condor DAG / Executable workflow that consists of Jobs. In case of Clustering, multiple tasks in the DAX can be captured into a single job in the Executable workflow. When DAGMan executes a job, a job instance is populated. Job instances capture information as seen by DAGMan. In case DAGMan retries a job when detecting a failure, a new job instance is populated. When DAGMan finds a job instance has finished, an invocation is associated with the job instance. In case of a clustered job, multiple invocations will be associated with a single job instance. If a Pre script or Post Script is associated with a job instance, then invocations are populated in the database for the corresponding job instance.
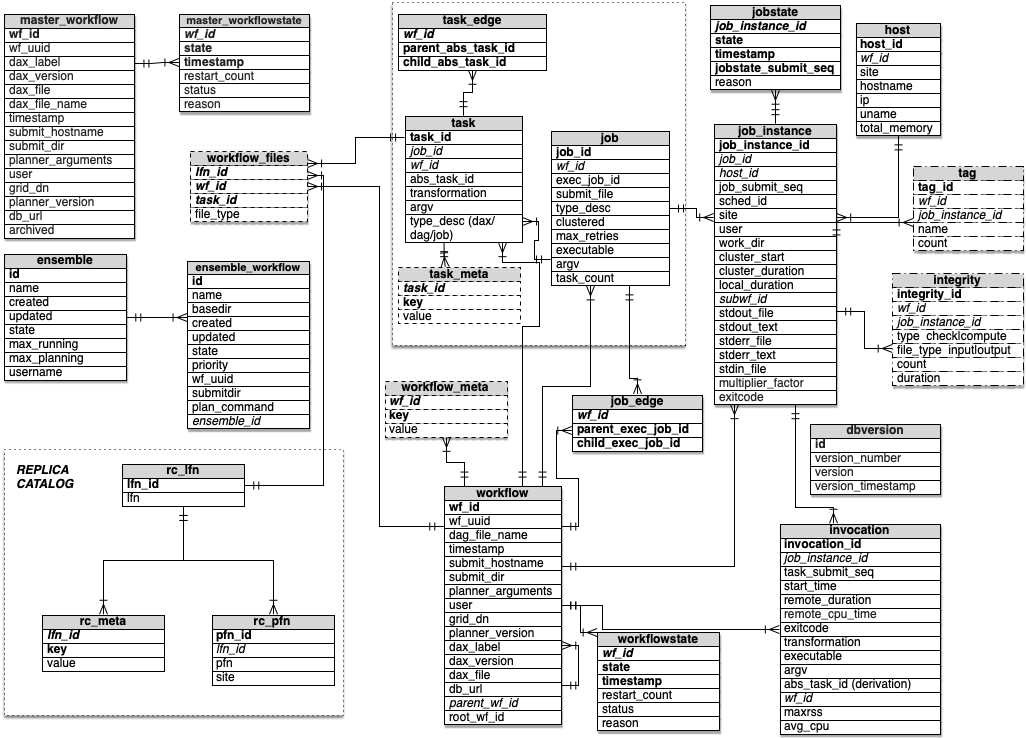
Workflow Database Schema
6.1.2.1. Storing of Exitcode in the database
Kickstart records capture raw status in addition to the exitcode. The
exitcode is derived from the raw status. Since Pegasus 4.0,
all exitcode columns (i.e., invocation and job instance table
columns) are stored with the raw status by pegasus-monitord. If an
exitcode is encountered while parsing the dagman log files, the value
is converted to the corresponding raw status before it is stored. All
user tools, pegasus-analyzer and pegasus-statistics then convert
the raw status to exitcode when retrieving from the database.
6.1.2.2. Multiplier Factor
Since Pegasus 4.0, there is a multiplier factor associated with the
jobs in the job_instance table. It defaults to one, unless the
user associates a Pegasus profile key named cores with the job in
the abstract workflow. The factor can be used for getting more accurate
statistics for jobs that run on multiple processors/cores or mpi jobs.
The multiplier factor is used for computing the following metrics by pegasus statistics:
In the summary, the workflow cumulative job wall time
In the summary, the cumulative job wall time as seen from the submit side.
In the jobs file, the multiplier factor is listed along-with the multiplied kickstart time.
In the breakdown file, where statistics are listed per transformation the mean, min, max, and average values take into account the multiplier factor.
6.2. Stampede Workflow Events
All the events generated by the system ( Pegasus planner and monitoring daemon) are formatted as Netlogger BP events. The netlogger events that Pegasus generates are described in Yang schema file that can be found in the share/pegasus/schema/ directory. The stampede yang schema is described below.
6.2.1. Typedefs
The following typedefs are used in the yang schema to describe the certain event attributes.
distinguished-name
typedef distinguished-name { type string; }
uuid
typedef uuid { type string { length "36"; pattern '[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}'; } }
intbool
typedef intbool { type uint8 { range "0 .. 1"; } }
nl_ts
typedef nl_ts { type string { pattern '(\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}(\.\d+)?(Z|[\+\-]\d{2}:\d{2}))|(\d{1,9}(\.\d+)?)'; } }
peg_inttype
typedef peg_inttype { type uint8 { range "0 .. 11"; } }
peg_strtype
typedef peg_strtype { type enumeration { enum "unknown" { value 0; } enum "compute" { value 1; } enum "stage-in-tx" { value 2; } enum "stage-out-tx" { value 3; } enum "registration" { value 4; } enum "inter-site-tx" { value 5; } enum "create-dir" { value 6; } enum "staged-compute" { value 7; } enum "cleanup" { value 8; } enum "chmod" { value 9; } enum "dax" { value 10; } enum "dag" { value 11; } } }
condor_jobstates
typedef condor_jobstates { type enumeration { enum "PRE_SCRIPT_STARTED" { value 0; } enum "PRE_SCRIPT_TERMINATED" { value 1; } enum "PRE_SCRIPT_SUCCESS" { value 2; } enum "PRE_SCRIPT_FAILED" { value 3; } enum "SUBMIT" { value 4; } enum "GRID_SUBMIT" { value 5; } enum "GLOBUS_SUBMIT" { value 6; } enum "SUBMIT_FAILED" { value 7; } enum "EXECUTE" { value 8; } enum "REMOTE_ERROR" { value 9; } enum "IMAGE_SIZE" { value 10; } enum "JOB_TERMINATED" { value 11; } enum "JOB_SUCCESS" { value 12; } enum "JOB_FAILURE" { value 13; } enum "JOB_HELD" { value 14; } enum "JOB_EVICTED" { value 15; } enum "JOB_RELEASED" { value 16; } enum "POST_SCRIPT_STARTED" { value 17; } enum "POST_SCRIPT_TERMINATED" { value 18; } enum "POST_SCRIPT_SUCCESS" { value 19; } enum "POST_SCRIPT_FAILED" { value 20; } } }
condor_wfstates
typedef condor_wfstates { type enumeration { enum "WORKFLOW_STARTED" { value 0; } enum "WORKFLOW_TERMINATED" { value 1; } } }
6.2.2. Groupings
Groupings are groups of common attributes that different type of events refer to. The following groupings are defined.
base-event - Common components in all events
ts - Timestamp, ISO8601 or numeric seconds since 1/1/1970
level - Severity level of event. Subset of NetLogger BP levels. For ‘*.end’ events, if status is non-zero then level should be Error.”
xwf.id - DAG workflow UUID
grouping base-event { description "Common components in all events"; leaf ts { type nl_ts; mandatory true; description "Timestamp, ISO8601 or numeric seconds since 1/1/1970"; } leaf level { type enumeration { enum "Info" { value 0; } enum "Error" { value 1; } } description "Severity level of event. " + "Subset of NetLogger BP levels. " + "For '*.end' events, if status is non-zero then level should be Error."; } leaf xwf.id { type uuid; description "DAG workflow id"; } } // grouping base-event
base-job-inst - Common components for all job instance events
all attributes from base-event
job_inst.id - Job instance identifier i.e the submit sequence generated by monitord.
js.id - Jobstate identifier
job.id - Identifier for corresponding job in the DAG
grouping base-job-inst { description "Common components for all job instance events"; uses base-event; leaf job_inst.id { type int32; mandatory true; description "Job instance identifier i.e the submit sequence generated by monitord"; } leaf js.id { type int32; description "Jobstate identifier"; } leaf job.id { type string; mandatory true; description "Identifier for corresponding job in the DAG"; } }
sched-job-inst - Scheduled job instance.
all attributes from base-job-inst
sched.id - Identifier for job in scheduler
grouping sched-job-inst { description "Scheduled job instance"; uses base-job-inst; leaf sched.id { type string; mandatory true; description "Identifier for job in scheduler"; } }
base-metadata
uses
key
value
grouping base-metadata { description "Common components for all metadata events that describe metadata for an entity."; uses base-event; leaf key { type string; mandatory true; description "Key for the metadata tuple"; } leaf value { type string; description "Corresponding value of the key"; } } // grouping base-metadata
6.2.3. Events
The system generates following types of events, that are described below.
The events are described in detail below
stampede.wf.plan
container stampede.wf.plan { uses base-event; leaf submit.hostname { type inet:host; mandatory true; description "The hostname of the Pegasus submit host"; } leaf dax.label { type string; default "workflow"; description "Label for abstract workflow specification"; } leaf dax.index { type string; default "workflow"; description "Index for the DAX"; } leaf dax.version { type string; mandatory true; description "Version number for DAX"; } leaf dax.file { type string; mandatory true; description "Filename for for the DAX"; } leaf dag.file.name { type string; mandatory true; description "Filename for the DAG"; } leaf planner.version { type string; mandatory true; description "Version string for Pegasus planner, e.g. 3.0.0cvs"; } leaf grid_dn { type distinguished-name; description "Grid DN of submitter"; } leaf user { type string; description "User name of submitter"; } leaf submit.dir { type string; mandatory true; description "Directory path from which workflow was submitted"; } leaf argv { type string; description "All arguments given to planner on command-line"; } leaf parent.xwf.id { type uuid; description "Parent workflow in DAG, if any"; } leaf root.xwf.id { type string; mandatory true; description "Root of workflow hierarchy, in DAG. " + "Use this workflow's UUID if it is the root"; } } // container stampede.wf.plan
stampede.static.start
container stampede.static.start { uses base-event; }
stampede.static.end
container stampede.static.end { uses base-event; } //
stampede.xwf.start
container stampede.xwf.start { uses base-event; leaf restart_count { type uint32; mandatory true; description "Number of times workflow was restarted (due to failures)"; } } // container stampede.xwf.start
stampede.xwf.end
container stampede.xwf.end { uses base-event; leaf restart_count { type uint32; mandatory true; description "Number of times workflow was restarted (due to failures)"; } leaf status { type int16; mandatory true; description "Status of workflow. 0=success, -1=failure"; } } // container stampede.xwf.end
stampede.task.info
container stampede.task.info { description "Information about task in DAX"; uses base-event; leaf transformation { type string; mandatory true; description "Logical name of the underlying executable"; } leaf argv { type string; description "All arguments given to transformation on command-line"; } leaf type { type peg_inttype; mandatory true; description "Type of task"; } leaf type_desc { type peg_strtype; mandatory true; description "String description of task type"; } leaf task.id { type string; mandatory true; description "Identifier for this task in the DAX"; } } // container stampede.task.info
stampede.task.edge
container stampede.task.edge { description "Represents child/parent relationship between two tasks in DAX"; uses base-event; leaf parent.task.id { type string; mandatory true; description "Parent task"; } leaf child.task.id { type string; mandatory true; description "Child task"; } } // container stampede.task.edge
stampede.wf.map.task_job
container stampede.wf.map.task_job { description "Relates a DAX task to a DAG job."; uses base-event; leaf task.id { type string; mandatory true; description "Identifier for the task in the DAX"; } leaf job.id { type string; mandatory true; description "Identifier for corresponding job in the DAG"; } } // container stampede.wf.map.task_job
stampede.xwf.map.subwf_job
container stampede.xwf.map.subwf_job { description "Relates a sub workflow to the corresponding job instance"; uses base-event; leaf subwf.id { type string; mandatory true; description "Sub Workflow Identified / UUID"; } leaf job.id { type string; mandatory true; description "Identifier for corresponding job in the DAG"; } leaf job_inst.id { type int32; mandatory true; description "Job instance identifier i.e the submit sequence generated by monitord"; } } // container stampede.xwf.map.subwf_job
stampede.job.info
container stampede.job.info { description "A description of a job in the DAG"; uses base-event; leaf job.id { type string; mandatory true; description "Identifier for job in the DAG"; } leaf submit_file { type string; mandatory true; description "Name of file being submitted to the scheduler"; } leaf type { type peg_inttype; mandatory true; description "Type of task"; } leaf type_desc { type peg_strtype; mandatory true; description "String description of task type"; } leaf clustered { type intbool; mandatory true; description "Whether job is clustered or not"; } leaf max_retries { type uint32; mandatory true; description "How many retries are allowed for this job before giving up"; } leaf task_count { type uint32; mandatory true; description "Number of DAX tasks for this job. " + "Auxiliary jobs without a task in the DAX will have the value '0'"; } leaf executable { type string; mandatory true; description "Program to execute"; } leaf argv { type string; description "All arguments given to executable (on command-line)"; } } // container stampede.job.info
stampede.job.edge
container stampede.job.edge { description "Parent/child relationship between two jobs in the DAG"; uses base-event; leaf parent.job.id { type string; mandatory true; description "Parent job"; } leaf child.job.id { type string; mandatory true; description "Child job"; } } // container stampede.job.edge
stampede.job_inst.pre.start
container stampede.job_inst.pre.start { description "Start of a prescript for a job instance"; uses base-job-inst; } // container stampede.job_inst.pre.start
stampede.job_inst.pre.term
container stampede.job_inst.pre.term { description "Job prescript is terminated (success or failure not yet known)"; } // container stampede.job_inst.pre.term
stampede.job_inst.pre.end
container stampede.job_inst.pre.end { description "End of a prescript for a job instance"; uses base-job-inst; leaf status { type int32; mandatory true; description "Status of prescript. 0 is success, -1 is error"; } leaf exitcode { type int32; mandatory true; description "the exitcode with which the prescript exited"; } } // container stampede.job_inst.pre.end
stampede.job_inst.submit.start
container stampede.job_inst.submit.start { description "When job instance is going to be submitted. " + "Scheduler job id is not yet known"; uses sched-job-inst; } // container stampede.job_inst.submit.start
stampede.job_inst.submit.end
container stampede.job_inst.submit.end { description "When executable job is submitted"; uses sched-job-inst; leaf status { type int16; mandatory true; description "Status of workflow. 0=success, -1=failure"; } } // container stampede.job_inst.submit.end
stampede.job_inst.held.start
container stampede.job_inst.held.start { description "When Condor holds the jobs"; uses sched-job-inst; } // container stampede.job_inst.held.start
stampede.job_inst.held.end
container stampede.job_inst.held.end { description "When the job is released after being held"; uses sched-job-inst; leaf status { type int16; mandatory true; description "Status of workflow. 0=success, -1=failure"; } } // container stampede.job_inst.held.end
stampede.job_inst.main.start
container stampede.job_inst.main.start { description "Start of execution of a scheduler job"; uses sched-job-inst; leaf stdin.file { type string; description "Path to file containing standard input of job"; } leaf stdout.file { type string; mandatory true; description "Path to file containing standard output of job"; } leaf stderr.file { type string; mandatory true; description "Path to file containing standard error of job"; } } // container stampede.job_inst.main.start
stampede.job_inst.main.term
container stampede.job_inst.main.term { description "Job is terminated (success or failure not yet known)"; uses sched-job-inst; leaf status { type int32; mandatory true; description "Execution status. 0=means job terminated, -1=job was evicted, not terminated"; } } // container stampede.job_inst.main.term
stampede.job_inst.main.end
container stampede.job_inst.main.end { description "End of main part of scheduler job"; uses sched-job-inst; leaf stdin.file { type string; description "Path to file containing standard input of job"; } leaf stdout.file { type string; mandatory true; description "Path to file containing standard output of job"; } leaf stdout.text { type string; description "Text containing output of job"; } leaf stderr.file { type string; mandatory true; description "Path to file containing standard error of job"; } leaf stderr.text { type string; description "Text containing standard error of job"; } leaf user { type string; description "Scheduler's name for user"; } leaf site { type string; mandatory true; description "DAX name for the site at which the job ran"; } leaf work_dir { type string; description "Path to working directory"; } leaf local.dur { type decimal64 { fraction-digits 6; } units "seconds"; description "Duration as seen at the local node"; } leaf status { type int32; mandatory true; description "Execution status. 0=success, -1=failure"; } leaf exitcode { type int32; mandatory true; description "the exitcode with which the executable exited"; } leaf multiplier_factor { type int32; mandatory true; description "the multiplier factor for use in statistics"; } leaf cluster.start { type nl_ts; description "When the enclosing cluster started"; } leaf cluster.dur { type decimal64 { fraction-digits 6; } units "seconds"; description "Duration of enclosing cluster"; } } // container stampede.job_inst.main.end
stampede.job_inst.post.start
container stampede.job_inst.post.start { description "Start of a postscript for a job instance"; uses sched-job-inst; } // container stampede.job_inst.post.start
stampede.job_inst.post.term
container stampede.job_inst.post.term { description "Job postscript is terminated (success or failure not yet known)"; uses sched-job-inst; } // container stampede.job_inst.post.term
stampede.job_inst.post.end
container stampede.job_inst.post.end { description "End of a postscript for a job instance"; uses sched-job-inst; leaf status { type int32; mandatory true; description "Status of postscript. 0 is success, -1=failure"; } leaf exitcode { type int32; mandatory true; description "the exitcode with which the postscript exited"; } } // container stampede.job_inst.post.end
stampede.job_inst.host.info
container stampede.job_inst.host.info { description "Host information associated with a job instance"; uses base-job-inst; leaf site { type string; mandatory true; description "Site name"; } leaf hostname { type inet:host; mandatory true; description "Host name"; } leaf ip { type inet:ip-address; mandatory true; description "IP address"; } leaf total_memory { type uint64; description "Total RAM on host"; } leaf uname { type string; description "Operating system name"; } } // container stampede.job_inst.host.info
stampede.job_inst.image.info
container stampede.job_inst.image.info { description "Image size associated with a job instance"; uses base-job-inst; leaf size { type uint64; description "Image size"; } leaf sched.id { type string; mandatory true; description "Identifier for job in scheduler"; } } // container stampede.job_inst.image.info
stampede.job_inst.tag
container stampede.job_inst.tag { description "A tag event to tag errors at a job_instance level"; uses base-job-inst; leaf name { type string; description "Name of tagged event such as int.error"; } leaf count { type int32; mandatory true; description "count of occurences of the events of type name for the job_instance"; } } // container stampede.job_inst.tag
stampede.job_inst.composite
container stampede.job_inst.composite{ description "A de-normalized composite event at the job_instance level that captures all the job information. Useful when populating AMQP"; uses base-job-inst; leaf jobtype { type string; description "Type of job as classified by the planner."; } leaf stdin.file { type string; description "Path to file containing standard input of job"; } leaf stdout.file { type string; mandatory true; description "Path to file containing standard output of job"; } leaf stdout.text { type string; description "Text containing output of job"; } leaf stderr.file { type string; mandatory true; description "Path to file containing standard error of job"; } leaf stderr.text { type string; description "Text containing standard error of job"; } leaf user { type string; description "Scheduler's name for user"; } leaf site { type string; mandatory true; description "DAX name for the site at which the job ran"; } leaf hostname { type inet:host; mandatory true; description "Host name"; } leaf { type string; description "Path to working directory"; } leaf local.dur { type decimal64 { fraction-digits 6; } units "seconds"; description "Duration as seen at the local node"; } leaf status { type int32; mandatory true; description "Execution status. 0=success, -1=failure"; } leaf exitcode { type int32; mandatory true; description "the exitcode with which the executable exited"; } leaf multiplier_factor { type int32; mandatory true; description "the multiplier factor for use in statistics"; } leaf cluster.start { type nl_ts; description "When the enclosing cluster started"; } leaf cluster.dur { type decimal64 { fraction-digits 6; } units "seconds"; description "Duration of enclosing cluster"; } leaf int_error_count { type int32; mandatory true; description "number of integrity errors encountered"; } } // container stampede.job_inst.composite
stampede.inv.start
container stampede.inv.start { description "Start of an invocation"; uses base-event; leaf job_inst.id { type int32; mandatory true; description "Job instance identifier i.e the submit sequence generated by monitord"; } leaf job.id { type string; mandatory true; description "Identifier for corresponding job in the DAG"; } leaf inv.id { type int32; mandatory true; description "Identifier for invocation. " + "Sequence number, with -1=prescript and -2=postscript"; } } // container stampede.inv.start
stampede.inv.end
container stampede.inv.end { description "End of an invocation"; uses base-event; leaf job_inst.id { type int32; mandatory true; description "Job instance identifier i.e the submit sequence generated by monitord"; } leaf inv.id { type int32; mandatory true; description "Identifier for invocation. " + "Sequence number, with -1=prescript and -2=postscript"; } leaf job.id { type string; mandatory true; description "Identifier for corresponding job in the DAG"; } leaf start_time { type nl_ts; description "The start time of the event"; } leaf dur { type decimal64 { fraction-digits 6; } units "seconds"; description "Duration of invocation"; } leaf remote_cpu_time { type decimal64 { fraction-digits 6; } units "seconds"; description "remote CPU time computed as the stime + utime"; } leaf exitcode { type int32; description "the exitcode with which the executable exited"; } leaf transformation { type string; mandatory true; description "Transformation associated with this invocation"; } leaf executable { type string; mandatory true; description "Program executed for this invocation"; } leaf argv { type string; description "All arguments given to executable on command-line"; } leaf task.id { type string; description "Identifier for related task in the DAX"; } } // container stampede.inv.end
stampede.int.metric
container stampede.int.metric { description "additional task events picked up from the job stdout"; uses base-event; leaf job_inst.id { type int32; mandatory true; description "Job instance identifier i.e the submit sequence generated by monitord"; } leaf job.id { type string; mandatory true; description "Identifier for corresponding job in the DAG"; } leaf type{ type string; description "enumerated type of metrics check|compute"; } leaf file_type{ type string; description "enumerated type of file types input|output"; } leaf count{ type int32; description "number of integrity events grouped by type , file_type "; } leaf duration{ type float; description "duration in seconds it took to perform these events "; } } // container stampede.int.metric
stampede.static.meta.start
container stampede.static.meta.start { uses base-event; } // container stampede.static.meta.start
stampede.static.meta.end
container stampede.static.meta.end { uses base-event; } // container stampede.static.meta.end
stampede.xwf.meta
container stampede.xwf.meta { description "Metadata associated with a workflow"; uses base-metadata; } // container stampede.xwf.meta
stampede.task.meta
container stampede.task.meta { description "Metadata associated with a task"; uses base-metadata; leaf task.id { type string; description "Identifier for related task in the DAX"; } } // container stampede.task.meta
stampede.task.monitoring
container stampede.task.monitoring { description "additional task events picked up from the job stdout"; uses base-event; leaf job_inst.id { type int32; mandatory true; description "Job instance identifier i.e the submit sequence generated by monitord"; } leaf job.id { type string; mandatory true; description "Identifier for corresponding job in the DAG"; } leaf monitoring_event{ type string; description "the name of the monitoring event parsed from the job stdout"; } leaf key{ type string; description "user defined keys in their payload in the event defined in the job stdout"; } } // container stampede.task.meta
stampede.rc.meta
container stampede.rc.meta { description "Metadata associated with a file in the replica catalog"; uses base-metadata; leaf lfn.id { type string; description "Logical File Identifier for the file"; } } // container stampede.rc.meta
stampede.wf.map.file
container stampede.wf.map.file { description "Event that captures what task generates or consumes a particular file"; uses base-event; leaf lfn.id { type string; description "Logical File Identifier for the file"; } leaf task.id { type string; description "Identifier for related task in the DAX"; } } // container stampede.wf.map.file
6.3. Publishing to AMQP Message Servers
Theworkflow events generated by pegasus-monitordcan also be used to publish to an AMQP message server such as RabbitMQ in addition to the stampede workflow database.
Note
A thing to keep in mind. The workflow events are documented as conforming to the netlogger requirements. When events are pushed to an AMQP endpoint, the . in the keys are replaced by _ .
6.3.1. Configuration
In order to get pegasus-monitord to populate to a message queue, you can set the following property
pegasus.catalog.workflow.amqp.url amqp://[USERNAME:PASSWORD@]amqp.isi.edu[:port]/<exchange_name>
The routing key set for the messages matches the name of the stampede workflow event being sent. By default, if you enable AMQP population only the following events are sent to the server
stampede.job_inst.composite
stampede.job_inst.tag
stampede.inv.end
stampede.wf.plan
To configure additional events, you can specify a comma separated list of events that need to be sent using the property pegasus.catalog.workflow.amqp.events. For example
pegasus.catalog.workflow.amqp.events = stampede.xwf.*,stampede.static.*
Note
To get all events you can just specify * as the value to the property.
6.3.1.1. Monitord, RabbitMQ, ElasticSearch Example
The AMQP support in Monitord is still a work in progress, but even the current functionality provides basic support for getting the monitoring data into ElasticSearch. In our development environment, we use a RabbitMQ instance with a simple exhange/queue. The configuration required for Pegasus is:
# help Pegasus developers collect data on integrity failures
pegasus.monitord.encoding = json
pegasus.catalog.workflow.amqp.url = amqp://friend:donatedata@msgs.pegasus.isi.edu:5672/prod/workflows
On the other side of the queue, Logstash is configured to receive the messages and forward them to ElasticSearch. The Logstash pipeline looks something like:
input {
rabbitmq {
type => "workflow-events"
host => "msg.pegasus.isi.edu"
vhost => "prod"
queue => "workflows-es"
heartbeat => 30
durable => true
password => "XXXXXX"
user => "prod-logstash"
}
}
filter {
if [type] == "workflow-events" {
mutate {
convert => {
"dur" => "float"
"remote_cpu_time" => "float"
}
}
date {
# set @timestamp from the ts of the actual event
match => [ "ts", "UNIX" ]
}
date {
match => [ "start_time", "UNIX" ]
target => "start_time_human"
}
fingerprint {
# create unique document ids
source => "ts"
concatenate_sources => true
method => "SHA1"
key => "Pegasus Event"
target => "[@metadata][fingerprint]"
}
}
}
output {
if [type] == "workflow-events" {
elasticsearch {
"hosts" => ["es1.isi.edu:9200", "es2.isi.edu:9200"]
"sniffing" => false
"document_type" => "workflow-events"
"document_id" => "%{[@metadata][fingerprint]}"
"index" => "workflow-events-%{+YYYY.MM.dd}"
"template" => "/usr/share/logstash/templates/workflow-events.json"
"template_name" => "workflow-events-*"
"template_overwrite" => true
}
}
}
Once the data is ElasticSearch, you can easily create for example Grafana dashboard like:
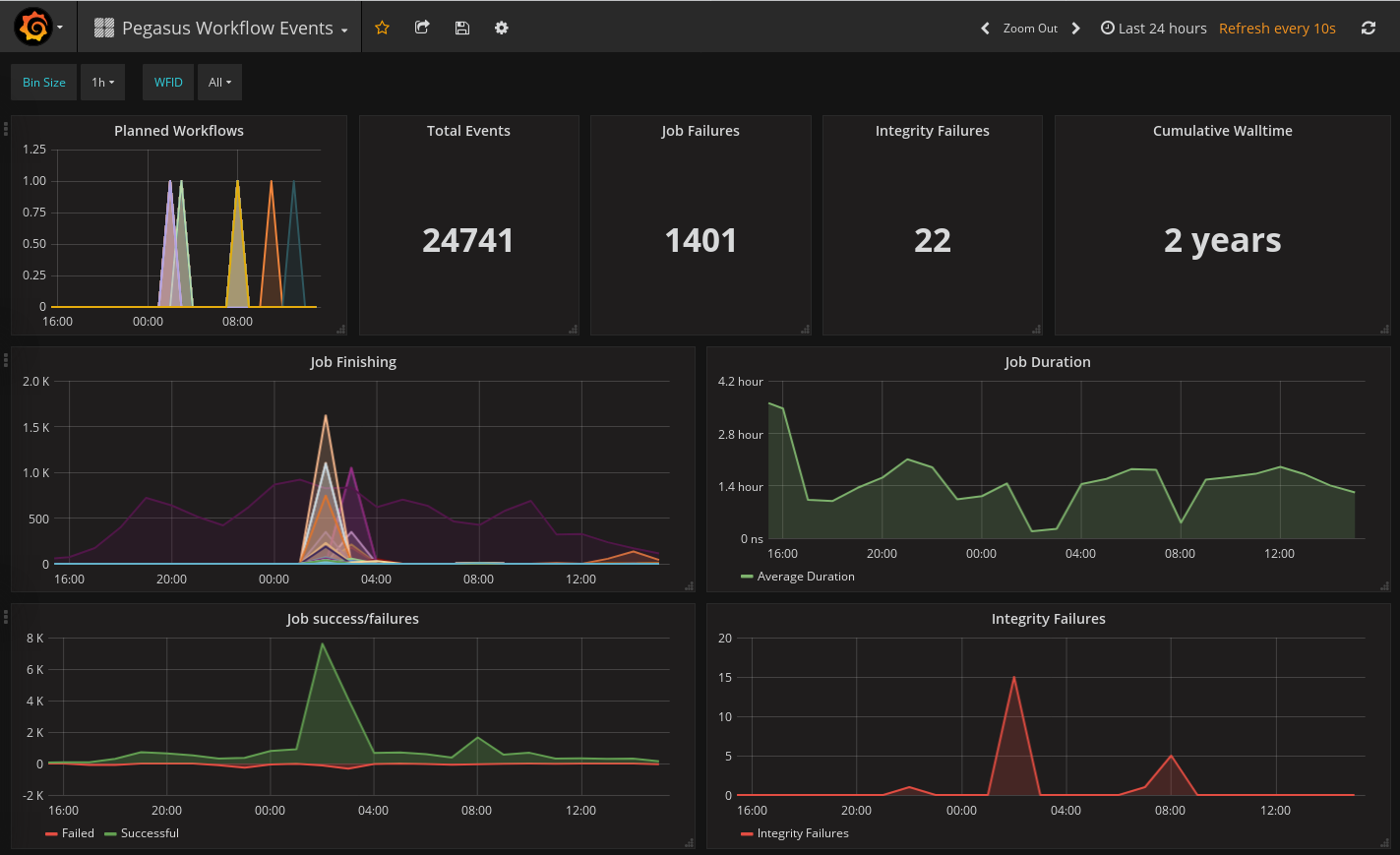
Grafana Dashboard
6.3.1.2. A Pre-Configured Data Collection Pipeline
In this repository, we provide a containerized data-collection/visualization pipeline similar to what we use in production. The figure below illustrates the processes involved in the pipeline and how they are connected to one another. For more information regarding setup and usage, please visit the link referenced above.
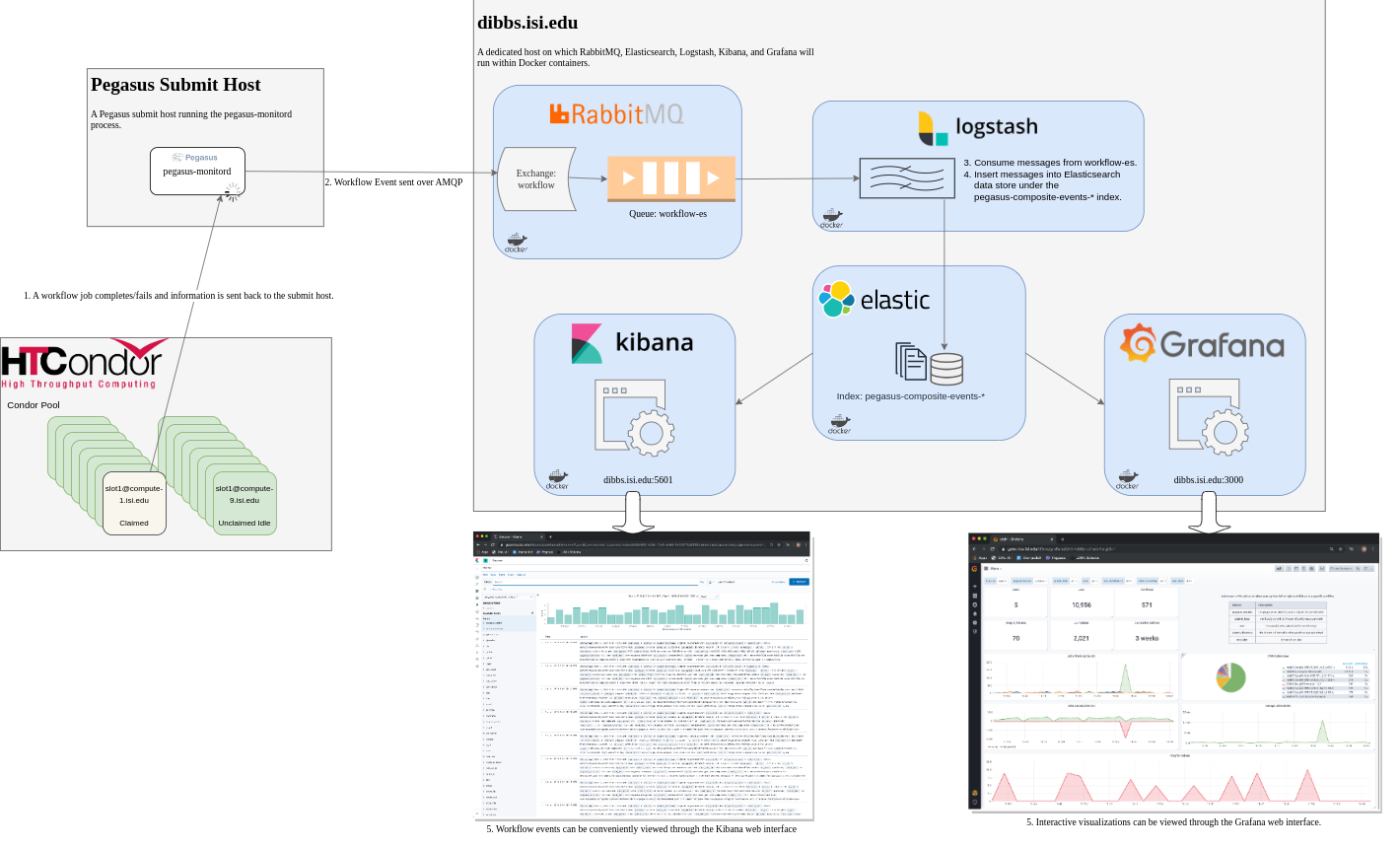
Data Collection/Visualization Pipeline