7. Running Workflows
7.1. Executable Workflows (DAG)
The DAG is an executable (concrete) workflow that can be executed over a variety of resources. When the workflow tasks are mapped to your target resources, explicit nodes are added to the workflow for orchestrating data transfer between the tasks; performing data cleanups and registration of outputs.
When you take the Abstract Workflow created in Creating Workflows, and plan it for a single remote grid execution, in this case for a site with handle hpcc, and plan the workflow without clean-up nodes, the following executable workflow is built:
Planning augments the original abstract workflow with ancillary tasks to facilitate the proper execution of the workflow. These tasks include:
the creation of remote working directories. These directories typically have name that seeks to avoid conflicts with other simultaneously running similar workflows. Such tasks use a job prefix of
create_dir.the stage-in of input files before any task which requires these files. Any file consumed by a task needs to be staged to the task, if it does not already exist on that site. Such tasks use a job prefix of
stage_in.If multiple files from various sources need to be transferred, multiple stage-in jobs will be created. Additional advanced options permit to control the size and number of these jobs, and whether multiple compute tasks can share stage-in jobs.the original compute task is concretized into a compute job in the DAG. Compute jobs are a concatination of the job’s name and id attribute from the input Abstract Workflow file.
the stage-out of data products to one or more output sites. Data products with their stageOut flag set to
falsewill not be staged to the output sites. However, they may still be eligible for staging to other, dependent tasks. Stage-out tasks use a job prefix ofstage_out.If compute jobs run at different sites, an intermediary staging task with prefix
stage_interis inserted between the compute jobs in the workflow, ensuring that the data products of the parent are available to the child job.the registration of data products in an output replica catalog. Data products with their register flag set to
falsewill not be registered.the clean-up of transient files and working directories. These steps can be omitted with the
--no-cleanupoption to the planner.
The Data Management chapter details more about when and how staging nodes are inserted into the workflow.
The DAG will be found in file diamond-0.dag, constructed from the
name and index attributes found in the root element of the
Abstract Workflow file.
######################################################################
# PEGASUS WMS GENERATED DAG FILE
# DAG diamond
# Index = 0, Count = 1
######################################################################
JOB create_dir_diamond_0_hpcc create_dir_diamond_0_hpcc.sub
SCRIPT POST create_dir_diamond_0_hpcc /opt/pegasus/default/bin/pegasus-exitcode create_dir_diamond_0_hpcc.out
JOB stage_in_local_hpcc_0 stage_in_local_hpcc_0.sub
SCRIPT POST stage_in_local_hpcc_0 /opt/pegasus/default/bin/pegasus-exitcode stage_in_local_hpcc_0.out
JOB preprocess_ID000001 preprocess_ID000001.sub
SCRIPT POST preprocess_ID000001 /opt/pegasus/default/bin/pegasus-exitcode preprocess_ID000001.out
JOB findrange_ID000002 findrange_ID000002.sub
SCRIPT POST findrange_ID000002 /opt/pegasus/default/bin/pegasus-exitcode findrange_ID000002.out
JOB findrange_ID000003 findrange_ID000003.sub
SCRIPT POST findrange_ID000003 /opt/pegasus/default/bin/pegasus-exitcode findrange_ID000003.out
JOB analyze_ID000004 analyze_ID000004.sub
SCRIPT POST analyze_ID000004 /opt/pegasus/default/bin/pegasus-exitcode analyze_ID000004.out
JOB stage_out_local_hpcc_2_0 stage_out_local_hpcc_2_0.sub
SCRIPT POST stage_out_local_hpcc_2_0 /opt/pegasus/default/bin/pegasus-exitcode stage_out_local_hpcc_2_0.out
PARENT findrange_ID000002 CHILD analyze_ID000004
PARENT findrange_ID000003 CHILD analyze_ID000004
PARENT preprocess_ID000001 CHILD findrange_ID000002
PARENT preprocess_ID000001 CHILD findrange_ID000003
PARENT analyze_ID000004 CHILD stage_out_local_hpcc_2_0
PARENT stage_in_local_hpcc_0 CHILD preprocess_ID000001
PARENT create_dir_diamond_0_hpcc CHILD findrange_ID000002
PARENT create_dir_diamond_0_hpcc CHILD findrange_ID000003
PARENT create_dir_diamond_0_hpcc CHILD preprocess_ID000001
PARENT create_dir_diamond_0_hpcc CHILD analyze_ID000004
PARENT create_dir_diamond_0_hpcc CHILD stage_in_local_hpcc_0
######################################################################
# End of DAG
######################################################################
The DAG file declares all jobs and links them to a Condor submit file that describes the planned, concrete job. In the same directory as the DAG file are all Condor submit files for the jobs from the picture plus a number of additional helper files.
The various instructions that can be put into a DAG file are described in Condor’s DAGMAN documentation. The constituents of the submit directory are described in the “Submit Directory Details”section
7.2. Data Staging Configuration
Pegasus can be broadly setup to run workflows in the following configurations
Condor Pool Without a shared filesystem
This setup applies to a condor pool where the worker nodes making up a condor pool don’t share a filesystem. All data IO is achieved using Condor File IO. This is a special case of the non shared filesystem setup, where instead of using pegasus-transfer to transfer input and output data, Condor File IO is used. This is the default data staging configuration in Pegasus.
NonShared FileSystem
This setup applies to where the head node and the worker nodes of a cluster don’t share a filesystem. Compute jobs in the workflow run in a local directory on the worker node
Shared File System
This setup applies to where the head node and the worker nodes of a cluster share a filesystem. Compute jobs in the workflow run in a directory on the shared filesystem.
Note
The default data staging configuration was changed from sharedfs (Shared File System) to condorio (Condor Pool Without a shared filesystem) starting with Pegasus 5.0 release.
For the purposes of data configuration various sites, and directories are defined below.
Submit Host
The host from where the workflows are submitted . This is where Pegasus and Condor DAGMan are installed. This is referred to as the “local” site in the site catalog .
Compute Site
The site where the jobs mentioned in the DAX are executed. There needs to be an entry in the Site Catalog for every compute site. The compute site is passed to pegasus-plan using –sites option
Staging Site
A site to which the separate transfer jobs in the executable workflow ( jobs with stage_in , stage_out and stage_inter prefixes that Pegasus adds using the transfer refiners) stage the input data to and the output data from to transfer to the final output site. Currently, the staging site is always the compute site where the jobs execute.
Output Site
The output site is the final storage site where the users want the output data from jobs to go to. The output site is passed to pegasus-plan using the –output option. The stageout jobs in the workflow stage the data from the staging site to the final storage site.
Input Site
The site where the input data is stored. The locations of the input data are catalogued in the Replica Catalog, and the pool attribute of the locations gives us the site handle for the input site.
Workflow Execution Directory
This is the directory created by the create dir jobs in the executable workflow on the Staging Site. This is a directory per workflow per staging site. Currently, the Staging site is always the Compute Site.
Worker Node Directory
This is the directory created on the worker nodes per job usually by the job wrapper that launches the job.
You can specifiy the data configuration to use either in
properties - Specify the global property pegasus.data.configuration .
site catalog - Starting 4.5.0 release, you can specify pegasus profile key named data.configuration and associate that with your compute sites in the site catalog.
7.2.1. Condor Pool Without a Shared Filesystem
By default, Pegasus is setup to do your data transfers in this mode. This setup applies to a condor pool where the worker nodes making up a condor pool don’t share a filesystem. All data IO is achieved using Condor File IO. This is a special case of the non shared filesystem setup, where instead of using pegasus-transfer to transfer input and output data, Condor File IO is used.
Setup
Submit Host and staging site are same
head node and worker nodes of compute site don’t share a filesystem
Input Data is staged from remote sites.
Remote Output Site i.e site other than compute site. Can be submit host.
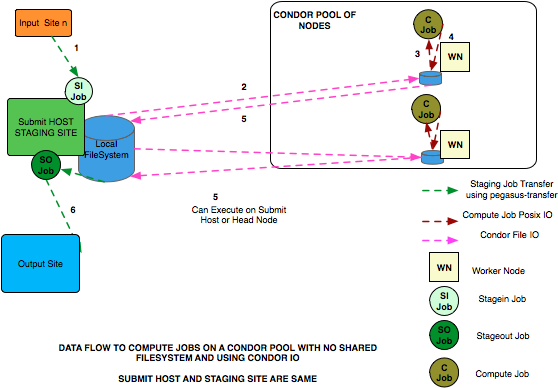
Condor Pool Without a Shared Filesystem
The data flow is as follows in this case
Stagein Job executes on the submit host to stage in input data from Input Sites ( 1—n) to a workflow specific execution directory on the submit host
Compute Job starts on a worker node in a local execution directory. Before the compute job starts, Condor transfers the input data for the job from the workflow execution directory on thesubmit host to the local execution directory on the worker node.
The compute job executes in the worker node, and executes on the worker node.
The compute Job writes out output data to the local directory on the worker node using Posix IO
When the compute job finishes, Condor transfers the output data for the job from the local execution directory on the worker node to the workflow execution directory on the submit host.
Stageout Job executes ( either on Submit Host or staging site ) to stage out output data from the workflow specific execution directory to a directory on the final output site.
In this case, the compute jobs are wrapped as PegasusLite instances.
This mode is especially useful for running in the cloud environments where you don’t want to setup a shared filesystem between the worker nodes. Running in that mode is explained in detail here.
Tip
Set pegasus.data.configuration to condorio to run in this configuration. In this mode, the staging site is automatically set to site local
In this setup, Pegasus always stages the input files through the submit host i.e the stage-in job stages in data from the input site to the submit host (local site). The input data is then transferred to remote worker nodes from the submit host using Condor file transfers. In the case, where the input data is locally accessible at the submit host i.e the input site and the submit host are the same, then it is possible to bypass the creation of separate stage in jobs that copy the data to the workflow specific directory on the submit host. Instead, Condor file transfers can be setup to transfer the input files directly from the locally accessible input locations ( file URL’s with “site” attribute set to local) specified in the replica catalog. More details can be found at Bypass Input File Staging.
In some cases, it might be useful to setup the PegasusLite jobs to pull input data directly from the input site without going through the staging server.
7.2.2. Non Shared Filesystem
In this setup , Pegasus runs workflows on local file-systems of worker nodes with the the worker nodes not sharing a filesystem. The data transfers happen between the worker node and a staging / data coordination site. The staging site server can be a file server on the head node of a cluster or can be on a separate machine.
Setup
compute and staging site are the different
head node and worker nodes of compute site don’t share a filesystem
Input Data is staged from remote sites.
Remote Output Site i.e site other than compute site. Can be submit host.
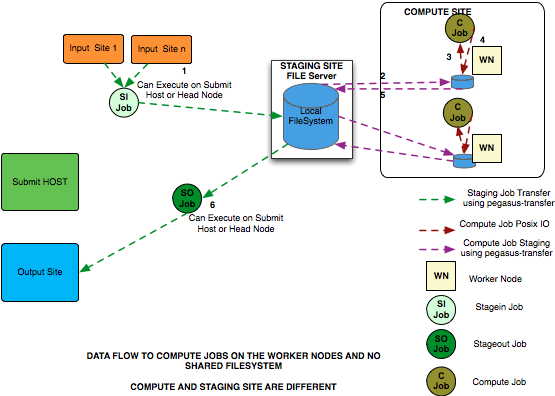
Non Shared Filesystem Setup
The data flow is as follows in this case
Stagein Job executes ( either on Submit Host or on staging site ) to stage in input data from Input Sites ( 1—n) to a workflow specific execution directory on the staging site.
Compute Job starts on a worker node in a local execution directory. Accesses the input data using pegasus transfer to transfer the data from the staging site to a local directory on the worker node
The compute job executes in the worker node, and executes on the worker node.
The compute Job writes out output data to the local directory on the worker node using Posix IO
Output Data is pushed out to the staging site from the worker node using pegasus-transfer.
Stageout Job executes ( either on Submit Host or staging site ) to stage out output data from the workflow specific execution directory to a directory on the final output site.
In this case, the compute jobs are wrapped as PegasusLite instances.
This mode is especially useful for running in the cloud environments where you don’t want to setup a shared filesystem between the worker nodes. Running in that mode is explained in detail here.
Tip
Set pegasus.data.configuration to nonsharedfs to run in this configuration. The staging site can be specified using the –staging-site option to pegasus-plan.
In this setup, Pegasus always stages the input files through the staging site i.e the stage-in job stages in data from the input site to the staging site. The PegasusLite jobs that start up on the worker nodes, then pull the input data from the staging site for each job. In some cases, it might be useful to setup the PegasusLite jobs to pull input data directly from the input site without going through the staging server. More details can be found at Bypass Input File Staging.
7.2.3. Shared File System
In this setup, Pegasus runs workflows in the shared file system setup, where the worker nodes and the head node of a cluster share a filesystem.
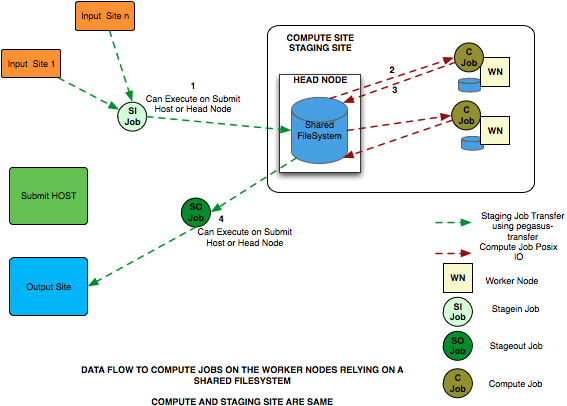
Shared File System Setup
The data flow is as follows in this case
Stagein Job executes ( either on Submit Host or Head Node ) to stage in input data from Input Sites ( 1—n) to a workflow specific execution directory on the shared filesystem.
Compute Job starts on a worker node in the workflow execution directory. Accesses the input data using Posix IO
Compute Job executes on the worker node and writes out output data to workflow execution directory using Posix IO
Stageout Job executes ( either on Submit Host or Head Node ) to stage out output data from the workflow specific execution directory to a directory on the final output site.
Tip
Set pegasus.data.configuration to sharedfs to run in this configuration.
7.3. Pegasus-Plan
pegasus-plan is the main executable that takes in the abstract workflow ( DAX ) and generates an executable workflow ( usually a Condor DAG ) by querying various catalogs and performing several refinement steps. Before users can run pegasus plan the following needs to be done:
Populate the various catalogs
Replica Catalog
The Replica Catalog needs to be catalogued with the locations of the input files required by the workflows. This can be done by using pegasus-rc-client (See the Replica section of Creating Workflows).
By default Pegasus picks up a file named replicas.yml in the current working directory ( from where pegasus-plan is invoked) as the Replica Catalog for planning.
Transformation Catalog
The Transformation Catalog needs to be catalogued with the locations of the executables that the workflows will use. This can be done by using pegasus-tc-client (See the Transformation section of Creating Workflows).
By default Pegasus picks up a file named transformations.yml in the current working directory ( from where pegasus-plan is invoked) as the Transformation Catalog for planning.
Site Catalog
The Site Catalog needs to be catalogued with the site layout of the various sites that the workflows can execute on. A site catalog can be generated for OSG by using the client pegasus-sc-client (See the Site section of the Creating Workflows).
By default Pegasus picks up a file named sites.yml in the current working directory ( from where pegasus-plan is invoked) as the Site Catalog for planning.
Configure Properties
After the catalogs have been configured, the user properties file need to be updated with the types and locations of the catalogs to use. These properties are described in the basic.properties files in the etc sub directory (see the Properties section of the Configuration chapter.
The basic properties that you may need to be set if using non default types and locations are for various catalogs are listed below:
Basic Properties that you may need to set pegasus.catalog.replica
type of replica catalog backend
pegasus.catalog.replica.file
path to replica catalog file
pegasus.catalog.transformation
type of transformation catalog
pegasus.catalog.transformation.file
path to transformation file
pegasus.catalog.site.file
path to site catalog file
pegasus.data.configuration
the data configuration mode for data staging.
To execute pegasus-plan user usually requires to specify the following options:
–dir the base directory where the executable workflow is generated
–sites comma separated list of execution sites. By default, Pegasus assumes a site named condorpool as your execution site.
–output the output site where to transfer the materialized output files.
–submit boolean value whether to submit the planned workflow for execution after planning is done.
the path to the DAX file that needs to be mapped.
7.4. Basic Properties
Properties are primarily used to configure the behavior of the Pegasus Workflow Planner at a global level. The properties file is actually a java properties file and follows the same conventions as that to specify the properties.
Please note that the values rely on proper capitalization, unless explicitly noted otherwise.
Some properties rely with their default on the value of other properties. As a notation, the curly braces refer to the value of the named property. For instance, ${pegasus.home} means that the value depends on the value of the pegasus.home property plus any noted additions. You can use this notation to refer to other properties, though the extent of the subsitutions are limited. Usually, you want to refer to a set of the standard system properties. Nesting is not allowed. Substitutions will only be done once.
There is a priority to the order of reading and evaluating properties. Usually one does not need to worry about the priorities. However, it is good to know the details of when which property applies, and how one property is able to overwrite another. The following is a mutually exclusive list ( highest priority first ) of property file locations.
–conf option to the tools. Almost all of the clients that use properties have a –conf option to specify the property file to pick up.
submit-dir/pegasus.xxxxxxx.properties file. All tools that work on the submit directory ( i.e after pegasus has planned a workflow) pick up the pegasus.xxxxx.properties file from the submit directory. The location for the pegasus.xxxxxxx.propertiesis picked up from the braindump file.
The properties defined in the user property file ${user.home}/.pegasusrc have lowest priority.
Starting Pegasus 5.0 release, pegasus properties can also be specified as environment variables. The properties specified by an environment variable have higher precedence than those specified in a properties file.
To specify a pegasus property as an environment variable you need to do the following:
Convert your property name to upper case
Replace . with __ .
Add a leading _ to the property name.
For example, to specify pegasus.catalog.replica in your environment you will specify
_PEGASUS__CATALOG__REPLICA__FILE = /path/to/replicas.yml
Commandline properties have the highest priority. These override any property loaded from a property file. Each commandline property is introduced by a -D argument. Note that these arguments are parsed by the shell wrapper, and thus the -D arguments must be the first arguments to any command. Commandline properties are useful for debugging purposes.
From Pegasus 3.1 release onwards, support has been dropped for the following properties that were used to signify the location of the properties file
pegasus.properties
pegasus.user.properties
- The basic properties that you may need to be set if using non default
types and locations are for various catalogs are listed below:
Basic Properties that you may need to set pegasus.catalog.replica
type of replica catalog backend
pegasus.catalog.replica.file
path to replica catalog file
pegasus.catalog.transformation
type of transformation catalog
pegasus.catalog.transformation.file
path to transformation file
pegasus.catalog.site.file
path to site catalog file
pegasus.data.configuration
the data configuration mode for data staging.
If you are in doubt which properties are actually visible, pegasus during the planning of the workflow dumps all properties after reading and prioritizing in the submit directory in a file with the suffix properties.
7.4.2. Catalog Related Properties
Key Attributes |
Description |
|---|---|
Property Key: pegasus.catalog.replica
Profile Key: N/A
Scope : Properties
Since : 2.0
Default : File
|
Pegasus queries a Replica Catalog to discover the
physical filenames (PFN) for input files specified in
the Abstract Workflow. Pegasus can interface with
various types of Replica Catalogs. This property
specifies which type of Replica Catalog to use during
the planning process.
JDBCRC
In this mode, Pegasus queries a SQL
based replica catalog that is accessed via JDBC.
To use JDBCRC, the user additionally needs to set
the following properties
pegasus.catalog.replica.db.driver = mysql | postgres|sqlite
pegasus.catalog.replica.db.url = <jdbc url to the database>
pegasus.catalog.replica.db.user = database-user
pegasus.catalog.replica.db.password = database-password
File
In this mode, Pegasus queries a file based
replica catalog. It is neither transactionally safe,
nor advised to use for production purposes in any way.
Multiple concurrent instances will clobber each other!.
The site attribute should be specified whenever possible.
The attribute key for the site attribute is “site”.
The LFN may or may not be quoted. If it contains
linear whitespace, quotes, backslash or an equality
sign, it must be quoted and escaped. Ditto for the
PFN. The attribute key-value pairs are separated by
an equality sign without any whitespaces. The value
may be in quoted. The LFN sentiments about quoting
apply.
To use File, the user additionally needs to specify
pegasus.catalog.replica.file property to
specify the path to the file based RC. IF not
specified , defaults to $PWD/rc.txt file.
YAML
This is the new YAML based file format
introduced in Pegasus 5.0. The format does support
regular expressions similar to Regex catalog type.
To specify regular expressions you need to associate
an attribute named regex and set to true.
To use YAML, the user additionally needs to specify
pegasus.catalog.replica.file property to
specify the path to the file based RC. IF not
specified , defaults to $PWD/replicas.yml file.
Regex
In this mode, Pegasus queries a file
based replica catalog. It is neither transactionally
safe, nor advised to use for production purposes in any
way. Multiple concurrent access to the File will end
up clobbering the contents of the file. The site
attribute should be specified whenever possible.
The attribute key for the site attribute is “site”.
The LFN may or may not be quoted. If it contains
linear whitespace, quotes, backslash or an equality
sign, it must be quoted and escaped. Ditto for the
PFN. The attribute key-value pairs are separated by
an equality sign without any whitespaces. The value
may be in quoted. The LFN sentiments about quoting
apply.
In addition users can specifiy regular expression
based LFN’s. A regular expression based entry should
be qualified with an attribute named ‘regex’. The
attribute regex when set to true identifies the
catalog entry as a regular expression based entry.
Regular expressions should follow Java regular
expression syntax.
For example, consider a replica catalog as shown below.
Entry 1 refers to an entry which does not use a regular
expressions. This entry would only match a file named
‘f.a’, and nothing else. Entry 2 referes to an entry
which uses a regular expression. In this entry f.a
refers to files having name as f[any-character]a
i.e. faa, f.a, f0a, etc.
Regular expression based entries also support
substitutions. For example, consider the regular
expression based entry shown below.
Entry 3 will match files with name alpha.csv,
alpha.txt, alpha.xml. In addition, values matched
in the expression can be used to generate a PFN.
For the entry below if the file being looked up is
alpha.csv, the PFN for the file would be generated as
file:///Volumes/data/input/csv/alpha.csv. Similary if
the file being lookedup was alpha.csv, the PFN for the
file would be generated as
The section [0], [1] will be replaced.
Section [0] refers to the entire string
i.e. alpha.csv. Section [1] refers to a partial
match in the input i.e. csv, or txt, or xml.
Users can utilize as many sections as they wish.
To use File, the user additionally needs to specify
pegasus.catalog.replica.file property to specify the
path to the file based RC.
Directory
In this mode, Pegasus does a directory
listing on an input directory to create the LFN to PFN
mappings. The directory listing is performed
recursively, resulting in deep LFN mappings.
For example, if an input directory $input is specified
with the following structure
Pegasus will create the mappings the following
LFN PFN mappings internally
If you don’t want the deep lfn’s to be created then,
you can set pegasus.catalog.replica.directory.flat.lfn
to true In that case, for the previous example, Pegasus
will create the following LFN PFN mappings internally.
pegasus-plan has –input-dir option that can be used
to specify an input directory.
Users can optionally specify additional properties to
configure the behvavior of this implementation.
- pegasus.catalog.replica.directory to specify
the path to the directory containing the files
- pegasus.catalog.replica.directory.site to
specify a site attribute other than local to
associate with the mappings.
- pegasus.catalog.replica.directory.url.prefix
MRC
In this mode, Pegasus queries multiple
replica catalogs to discover the file locations on the
grid. To use it set
pegasus.catalog.replica MRC
Each associated replica catalog can be configured via
properties as follows.
The user associates a variable name referred to as
[value] for each of the catalogs, where [value]
is any legal identifier
(concretely [A-Za-z][_A-Za-z0-9]*) . For each
associated replica catalogs the user specifies
the following properties.
In the above example, directory1, directory2 are any
valid identifier names and url is the property key that
needed to be specified.
|
Property Key: pegasus.catalog.replica.file.
Profile Key: N/A
Scope : Properties
Since : 2.0
Default : 1000
|
The path to a file based replica catalog backend
|
Key Attributes |
Description |
|---|---|
Property Key: pegasus.catalog.site
Profile Key: N/A
Scope : Properties
Type : Enumeration
Values : YAML|XML
Since : 2.0
Default : YAML
|
Pegasus supports two different types of site catalogs in
YAML or XML formats
Pegasus is able to auto-detect what schema a user site
catalog refers to. Hence, this property may no longer be set.
|
Property Key: pegasus.catalog.site.file
Profile Key : N/A
Scope : Properties
Since : 2.0
Default : $PWD/sites.yml | $PWD/sites.xml
|
The path to the site catalog file, that describes the various
sites and their layouts to Pegasus.
|
Key Attributes |
Description |
|---|---|
Property Key: pegasus.catalog.transformation
Profile Key: N/A
Scope : Properties
Since : 2.0
Type : Enumeration
Values : YAML|Text
Default : YAML
|
|
Property Key: pegasus.catalog.transformation
Profile Key : N/A
Scope : Properties
Since : 2.0
Default : $PWD/transformations.yml|$PWD/tc.txt
|
The path to the transformation catalog file, that
describes the locations of the executables.
|
7.4.3. Data Staging Configuration Properties
Key Attributes |
Description |
|---|---|
Property Key: pegasus.data.configuration
Profile Key:data.configuration
Scope : Properties, Site Catalog
Since : 4.0.0
Values : sharedfs|nonsharedfs|condorio
Default : condorio
See Also : pegasus.transfer.bypass.input.staging
|
This property sets up Pegasus to run in different
environments. For Pegasus 4.5.0 and above, users
can set the pegasus profile data.configuration with
the sites in their site catalog, to run multisite
workflows with each site having a different data
configuration.
If this is set, Pegasus will be setup to execute
jobs on the shared filesystem on the execution site.
This assumes, that the head node of a cluster and
the worker nodes share a filesystem. The staging
site in this case is the same as the execution site.
Pegasus adds a create dir job to the executable
workflow that creates a workflow specific
directory on the shared filesystem . The data
transfer jobs in the executable workflow
( stage_in_ , stage_inter_ , stage_out_ )
transfer the data to this directory.The compute
jobs in the executable workflow are launched in
the directory on the shared filesystem.
If this is set, Pegasus will be setup to run jobs
in a pure condor pool, with the nodes not sharing
a filesystem. Data is staged to the compute nodes
from the submit host using Condor File IO. The
planner is automatically setup to use the submit
host ( site local ) as the staging site. All the
auxillary jobs added by the planner to the
executable workflow ( create dir, data stagein
and stage-out, cleanup ) jobs refer to the workflow
specific directory on the local site. The data
transfer jobs in the executable workflow
( stage_in_ , stage_inter_ , stage_out_ )
transfer the data to this directory. When the
compute jobs start, the input data for each job is
shipped from the workflow specific directory on
the submit host to compute/worker node using
Condor file IO. The output data for each job is
similarly shipped back to the submit host from the
compute/worker node. This setup is particularly
helpful when running workflows in the cloud
environment where setting up a shared filesystem
across the VM’s may be tricky.
pegasus.gridstart PegasusLite
pegasus.transfer.worker.package true
**nonsharedfs**
If this is set, Pegasus will be setup to execute
jobs on an execution site without relying on a
shared filesystem between the head node and the
worker nodes. You can specify staging site
( using –staging-site option to pegasus-plan)
to indicate the site to use as a central
storage location for a workflow. The staging
site is independant of the execution sites on
which a workflow executes. All the auxillary
jobs added by the planner to the executable
workflow ( create dir, data stagein and
stage-out, cleanup ) jobs refer to the workflow
specific directory on the staging site. The
data transfer jobs in the executable workflow
( stage_in_ , stage_inter_ , stage_out_
transfer the data to this directory. When the
compute jobs start, the input data for each
job is shipped from the workflow specific
directory on the submit host to compute/worker
node using pegasus-transfer. The output data
for each job is similarly shipped back to the
submit host from the compute/worker node. The
protocols supported are at this time SRM,
GridFTP, iRods, S3. This setup is particularly
helpful when running workflows on OSG where
most of the execution sites don’t have enough
data storage. Only a few sites have large
amounts of data storage exposed that can be used
to place data during a workflow run. This setup
is also helpful when running workflows in the
cloud environment where setting up a
shared filesystem across the VM’s may be tricky.
On loading this property, internally the
following properies are set
pegasus.gridstart PegasusLite
pegasus.transfer.worker.package true
|