Cloud computing is a new way of thinking about large-scale computing infrastructure. It combines utility computing with virtualization to provide highly configurable computational resources for business and science applications.
There are many different cloud computing architectures in use. These include:
- Software as a Service (SaaS) — SaaS clouds such as Gmail provide an end-user application over the network.
- Platform as a Service (PaaS) — PaaS clouds such as Google AppEngine provide a hosting platform for users to deploy domain-specific applications (e.g. websites).
- Infrastructure as a Service (IaaS) — IaaS clouds such as Amazon EC2 provide low-level infrastructure services (compute, storage, network) that users can customize for any application.
Cloud computing is similar to, and offers many of the same advantages as, grid computing. Like grids, clouds separate the user from infrastructure concerns such as maintenance and administration. Unlike grids, clouds allow the user to customize many aspects of the software environment and provide many additional software services that are useful for science applications such as storage and database services.
Workflow and other science applications are just beginning to take advantage of the cloud computing model. Several IaaS clouds have been deployed for use by science applications and more are in the planning stages. The Pegasus team has been experimenting with IaaS clouds for workflow applications since 2008 [ 1, 2, 3, 4]. The latest version of Pegasus can be used to plan and execute workflows on commercial and academic IaaS clouds such as Amazon EC2, Nimbus, OpenNebula and Eucalyptus.
Virtualization
Infrastructure clouds such as Amazon EC2 rely on virtualization technology. In simple terms, virtualization allows a single physical machine to behave like multiple virtual machines (VMs). The use of virtualization produces many benefits, but the most significant is that a user can deploy customized software on hardware owned by the resource provider (e.g. Amazon). The user can control all of the software, including the OS, without worrying about hardware administration and maintenance.
Users customize their OS by creating a VM image. A VM image is like an archive that contains all of the files and programs used by the operating system. Since the user controls the contents of the VM image, they can customize all aspects of the software environment. For example, they can install components and libraries required by their application and create application-specific system configurations. In addition, the use of VM images promotes reproducibility in computational science applications. A VM image can be saved and reused for future experiments without the risk that software changes will produce different results.
Virtual Clusters
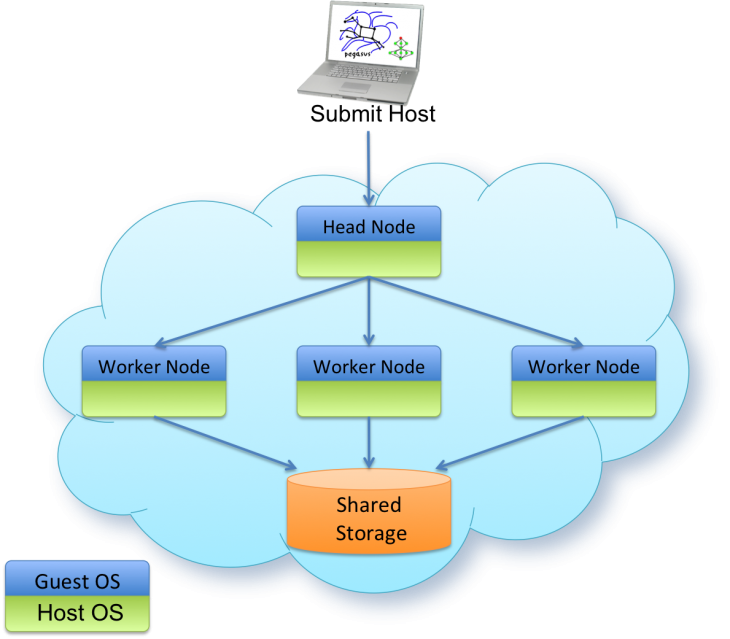
Many science applications require compute and storage resources beyond what can be provided by a single computer. These applications typically run on clusters, grids and supercomputers that can provide thousands of CPUs and terabytes of storage. Users of infrastructure clouds can recreate many of these same HPC architectures by deploying virtual clusters in the cloud [Figure 1]. Virtual clusters are compute clusters composed of virtual machines. They can be configured to be functionally identical to traditional clusters by using the exact same resource management software used by traditional clusters, such as PBS and Condor
One of the key challenges of running workflows in the cloud is how worker nodes communicate data between workflow tasks. On traditional grids and clusters this is typically accomplished using a network or parallel file system. The challenge in the cloud is how to either reproduce or replace these systems. File systems such as NFS, GlusterFS, and PVFS, can be deployed as part of a virtual cluster using configuration tools such as the Nimbus Context Broker. In addition, many clouds provide storage services that can be used for applications. For example, Amazon provides S3, an object-based storage system, and SimpleDB, a key-value storage system.
Workflows in the Cloud
Once a virtual cluster is deployed it can be used for running workflow applications. The simplest configuration for Pegasus is to deploy a virtual cluster with Condor and either NFS or GlusterFS for storage. The latest version of Pegasus also supports the use of Amazon S3.
Workflows in the cloud perform nearly as well as workflows in a traditional cluster or grid environment. In our experiments we have seen a virtualization overhead of less than 10% on all the workflows we have tested. Also, in our experience the reliability of clouds is much higher than that of grids.
Getting Started
Using a cloud like Amazon EC2 to run a workflow application is relatively straightforward. In about a day you can be up and running with a basic configuration. You will need:
- An Amazon EC2 account.
- A VM image containing Condor, Pegasus, Globus, and any libraries, configuration, or binaries required by the application. This image can be created by launching a stock VM image as an EC2 instance, installing the required software on the running instance, and then saving a snapshot of that instance as an image.
- A submit host running outside the cloud with Condor and Pegasus. This is the machine from which you will plan and submit your workflows.
- A shared storage system. Pegasus has built-in support for Amazon S3, or you can configure your VM image to deploy a traditional network file system on EC2. We have had great success with GlusterFS.
Once these items are in place you should be able to launch a virtual cluster to run your workflow.