These are simple examples that illustrate how to construct common data processing patterns in Pegasus workflows.
Each of the examples can be planned and executed using Pegasus on any standard UNIX system.The workflows can be generated, planned, and executed by running:
$ pegasus-init example-workflow
###########################################################
########### Available Execution Environments ##########
###########################################################
1) Local Machine Condor Pool
2) Local SLURM Cluster
3) Remote SLURM Cluster
4) Local LSF Cluster
5) Local SGE Cluster
6) OLCF Summit from OLCF Headnode
7) OLCF Summit from OLCF Hosted Kubernetes Pod
Select an execution environment [1]:
###########################################################
########### Available Workflow Examples ##########
###########################################################
1) pegasus-isi/diamond-workflow
2) pegasus-isi/hierarichal-sample-wf
3) pegasus-isi/merge-workflow
4) pegasus-isi/pipeline-workflow
5) pegasus-isi/process-workflow
6) pegasus-isi/split-workflow
Select an example workflow [1]:
There is a DAX file and a Python DAX generator for each example workflow.
Check the Pegasus User Guide for more information on writing workflow generators and more examples.
Process

The process workflow consists of a single job that runs the `ls` command and generates a listing of the files in the `/` directory.
Pipeline
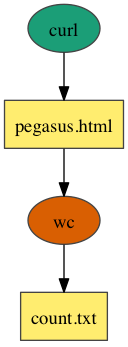
The pipeline workflow consists of two jobs linked together in a pipeline. The first job runs the `curl` command to fetch the Pegasus home page and store it as an HTML file. The result is passed to the `wc` command, which counts the number of lines in the HTML file.
Split
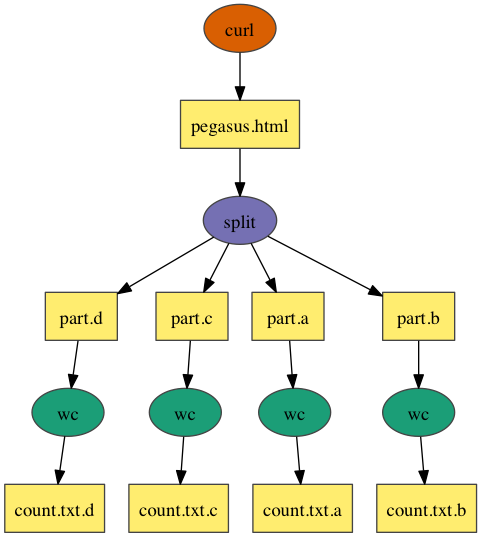
The split workflow downloads the Pegasus home page using the `curl` command, then uses the `split` command to divide it into 4 pieces. The result is passed to the `wc` command to count the number of lines in each piece.
Merge
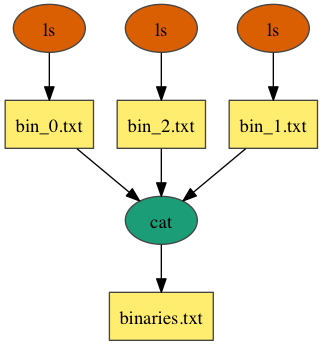
The merge workflow runs the `ls` command on several */bin directories and passes the results to the `cat` command, which merges the files into a single listing.