Authors: Patrycja Krawczuk (krawczuk@isi.edu), Shubham Nagarkar (slnagark@isi.edu)
Introduction
Floods, hurricanes, wildfires, cyclones, and blizzards are becoming more frequent and more severe as a result of global warming. Natural catastrophes necessitate immediate and focused emergency actions in order to preserve lives and minimize infrastructure damage. Social Media (SM) platforms are increasingly becoming important instruments for gathering data needed to find victims and organize effective emergency aid (see Fig.1), particularly in the early hours following a disaster’s start.
One of the most significant challenges in using SM content for crisis response is dealing with information overload. Because millions of SM posts are published at any given time, a system capable of processing enormous amounts of data in near real-time is required. A system of this type should be able to sift through thousands of short, informal messages and vast quantities of pictures to extract trustworthy SM postings that may be used to create situational awareness during a catastrophe event. Multimodal data exchanged on these channels frequently includes important information on the magnitude of the event, casualties, and infrastructure damage. The data can provide local authorities and humanitarian organizations with a big-picture understanding of the emergency (situational awareness). Moreover, it can be used to effectively and timely plan relief responses
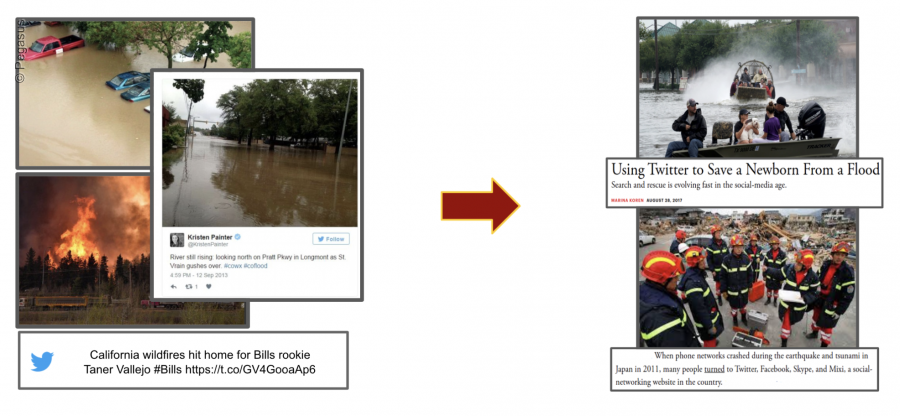

The goal of this workflow is to improve the accuracy of the existing deep learning methods on informative vs. non-informative classification tasks on the CrisisMMD dataset. CrisisFlow is a computational workflow capable of processing and classifying thousands of multimodal SM posts.
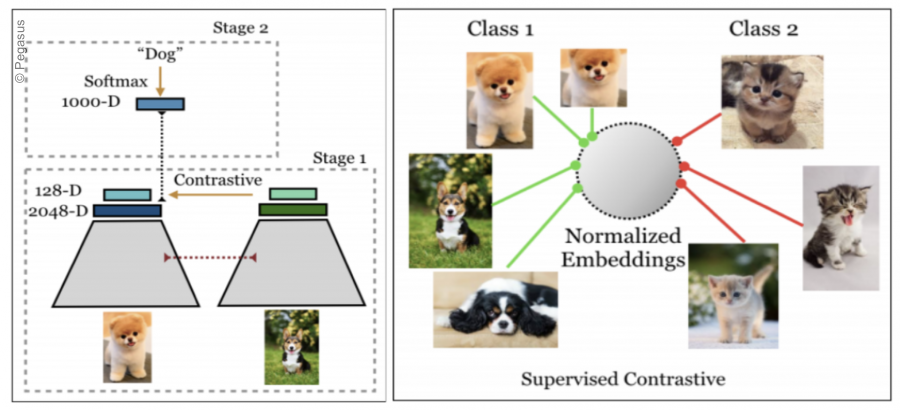
Contrastive learning
Contrastive learning techniques learn embeddings by pulling similar picture representations together and pushing dissimilar image representations apart in the latent space. When labeled data is unavailable, the technique is frequently used to solve issues. The SupCon model described in [4] is a semi-supervised architecture that makes use of labeled data using a new Supervised Contrastive Loss. When presented with a high number of negative instances (in our case non-informative pictures), the loss function is meant to improve its discriminatory power.
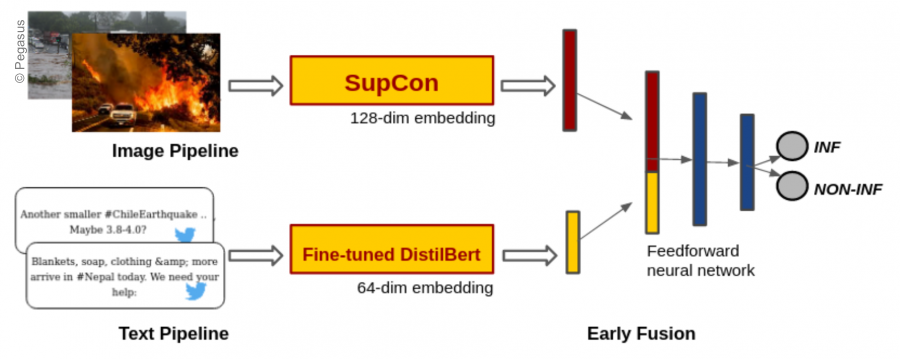
Multimodal learning: Early Fusion
Early fusion is a technique that allows merging data from different sources and modalities (image, text, audio) at a vector level. The multiple modalities often offer complementary information that helps to improve the performance of a model. The proposed architecture consists of two pipelines that ingest pictorial and textual parts of SM posts, respectively. The modalities serve as inputs to the architectures that generate the crisis-specific representations of the data as low-dimensional vectors. The image and text embeddings are concatenated and passed through a neural network that classifies the SM post as informative or non-informative.
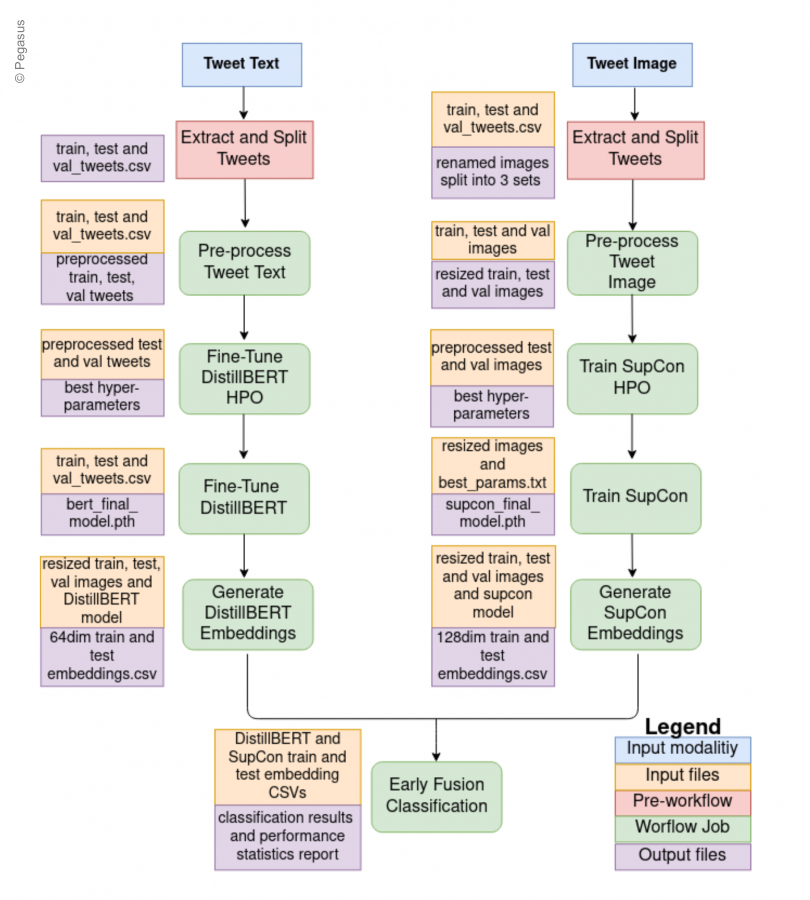
Crisis Workflow: CrisisFlow
To ensure the reliability and scalability of the proposed solution in real-world scenarios, we implement our method, CrisisFlow, in Pegasus WMS [6]. The directed acyclic graph (DAG) of the CrisisFlow where the nodes represent individual tasks while edges represent dependencies between them is depicted in Fig. 4. Pegasus automatically maps the DAG onto available distributed resources. Researchers can use CrisisFlow to train the binary classification models on their own SM data.
17th IEEE eScience 2021 International Conference Presentation
The above video shows the CrisisFlow Poster, which was presented by Patrycja Krawczuk and Shubham Nagarkar at the IEEE eScience conference on 22nd September, 2021.
References:
- M. Koren, ”Using Twitter To Save A Newborn From A Flood”. TheAtlantic, 2017.
- F. Alam, F. Ofli, M. Imran, ”CrisisMMD: Multimodal Twitter Datasetsfrom Natural Disasters”. Proceedings of the 12th International AAAI Conference on Web and Social Media (ICWSM), 2018.
- F. Ofli, F. Alam, M. Imran, ”Analysis of Social Media Data usingMultimodal Deep Learning for Disaster Response”. 17th International Conference on Information Systems for Crisis Response and Management (ISCRAM), 2020.
- P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y. Tian, P. Isola, A.Maschinot, C. Liu, D. Krishnan, ”Supervised Contrastive Learning” Conference on Neural Information Processing Systems (NeurIPS), 2020.
- V. Sanh, L. Debut, J. Chaumond, T. Wolf, ”DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter”, 2020.
- E. Deelman, K. Vahi, G. Juve, M. Rynge, S. Callaghan, P. Maechling,P. Mayani, W. Chen, R. Silva, M. Livny, K. Wenger, ”Pegasus: a Work-flow Management System for Science Automation”. Future Generation Computer Systems, 2015, pp. 17-35.