Date: Thursday, February 17th, 2022
Time: 8:00am – 9:00am PST
Location: ISI
Title
YML and Multi-Level Programming Paradigms using Graphs of Task
Abstract
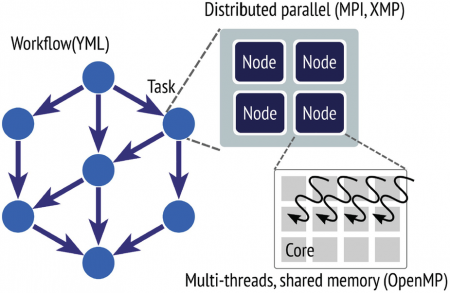
Exascale supercomputers will have highly hierarchical architectures with nodes composed by lot-of- core processors and often accelerators. Methods would often have to be redesigned and new ones introduced or rehabilitated in terms of communication optimizations and data distribution. New applications will require different arithmetic and new data managements.The different programming levels (from clusters of processors loosely connected to tightly connected lot-of-core processors and/or accelerators) will generate new difficult algorithm issues. New language and framework should be defined and evaluated with respect to modern state-of-the-art of scientific methods, including new machine learning ones. We propose YML, which allow to develop codes for multilevel programming paradigms, to explore extreme computing and avoid costly global communications and reductions.YML with its high level language permits to automate and delegate the managements of dependencies between loosely coupled clusters of processors to a specialized tool which controls the execution of the application. Besides, the tightly coupled processors inside each cluster could be programmed through a PGAS language such as XMP. Thanks to the component-oriented software architecture of YML, it is relatively easy to integrate new components such as numerical libraries, encapsulated XMP programs for lower level of the computer architecture, etc. Each of the components may also use runtime system or tools to use accelerators.In this talk, we present this multilevel programming paradigm and propose our approach based on YML. We discuss orchestration and scheduling strategies to develop in order to minimize communications and I/O. As example, we present the Block Gauss-Jordan method to invert dense matrices, and the Multiple Explicitly Restarted Arnoldi Method (MERAM) to compute eigenvalues of sparse matrices. We also propose experiments using components implemented in XMP and discuss projects using software to address accelerators. Experimental results are obtained on Japanese “K” and “T2K” supercomputers, on the French Grid5000 platform, and on the “Hooper” supercomputer in LBNL.We conclude, first, on the correctness of this approach and we point out, next, the performances of these methods on the targeted multi-level parallel architectures in the context of the YML/XMP multi languages integrated framework. On the K computer, we obtained much better results using YML and XMP than only XMP, illustrating the interest of our approach, even if supercomputers schedulers are not yet smarter enough to exploit YML graph analysis.Joint work with:, Mitsuhisa Sato and Miwako Tsuji (CCS, RIKEN, Kobe), Leroy Drummond (U. Berkeley), Maxime Hugues (TOTAL, Houston), Thomas Dufaud (U. Versailles-Paris Saclay) Jérôme Gurhem and Maxence Vandromme (MDLS@Saclay) and Takahiro Katigari (Univ. Tokyo).
Bio
Serge G. Petiton received the B.S. degree in mathematics, in 1982, the Ph.D. degree in computer science, in 1988, and the “Habilitation à diriger des recherches”, in 1993, from the Sorbonne University, Pierre et Marie Curie Campus. He was post-doc student, registered at the graduate school, and junior researcher scientist at Yale University, 1989-1990. He has been researcher at the “Site Experimental en Hyperparallelisme” (supported by CNRS, CEA, and French DoD) from 1991 to 1994. He also was affiliate research scientist at Yale and visiting research fellow in several US laboratories (NASA/ICASE, AHPCRC,..) during the period 1991-1994. Since 1994, Serge G. Petiton is tenured Full Professor at the University of Lille in France and, since 2012, he has a CNRS senior position at the “Maison de la Simulation” in Paris-Saclay. Serge G. Petiton has been scientific director of more than 25 Ph.D.s and has authored more than 140 articles on international journals, books, and conferences. Serge G. Petiton has several International research collaborations with Germany, US, Japan and China. He was invited Professor in 2016 at the Chinese Academy of Science. His main current research interests are in “Parallel and Distributed Computing”, “Post-Petascale Dense and Sparse Linear Algebra”, “Language and Programming Paradigm for Extreme Modern Scientific Computing”, and “Machine Learning”.