Author: Dino Bektešević, University of Washington, LSST/Rubin Observatory project
Overview
In 2020 the Data Intensive Research in Astrophysics and Cosmology institute (DIRAC), University of Washington (WA) Astronomy Department, Legacy Survey of Space and Time (LSST) and Amazon Web Services (AWS) joined forces to develop a proof-of-concept (PoC) leveraging cloud resources to processing astronomical images at scale. The AWS PoC’s goal was to implement required functionality that would enable Vera C. Rubin Observatory LSST Science Pipelines execution on AWS. The AWS PoC leveraged HTCondor Annex and Pegasus to successfully create and execute workflows in heterogeneous dynamically resizable compute clusters in order to determine feasibility, performance and provide initial cost estimates of such a system.
Rubin and LSST
Rubin Observatory is an 8m telescope currently under construction in Chile on which LSST sky survey will be conducted. The sky will be imaged by an incredible 3200 Megapixel camera capturing largest ever single-shot images. Because of it’s large field-of-view LSST will image the entire southern hemisphere of the sky every 3 nights over a period of 10 years.
Rubin estimates the size of nightly data products on the order of 20TB. Eventually, over the course of 10 years, it is estimated that Rubin will deliver 500 Petabytes (PB) of images and data products. How to process data and how to facilitate science at these data volumes are the two central questions of the Rubin Data Management (DM) team.
DM estimates that at the end of the ten-year survey they will use 950 TFLOPS (trillion floating point operations per second) to process all of the data and produce final Data Release 11. This processing is set to occur at two supercomputing facilities: SLAC National Accelerator Laboratory (SLAC) in US and CC-IN2P3 in France.
Around 10% of these resources will also be used to host services and provide data access to astronomers. Given the size of SLAC and CC-IN2P3 even the 10% of their resources is a significant amount of computational resources, but they are also not a one-size-fits-all solution. We wanted to investigate how we can give users access to state-of-the-art processing algorithms within Rubin DM data processing pipelines, can this be done in a way that scales to the size of Rubin and whether it can be affordable.
Middleware
Science Pipelines implement state of the art functionality in astronomical data reduction. They enable processing of data from a single exposure to joint calibration of multiple exposures for multiple different instruments, not just Rubin. The data processing algorithms are encapsulated in a concept known as a Task. A Task takes in a dataset as a Python object and performs some analysis on it, producing other datasets. Tasks can be chained in a pipeline represented by a directed acyclic graph (DAG) called a Quantum Graph (QG). Each node of a QG is a Task applied to an individual dataset.
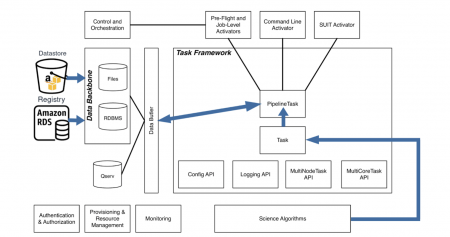
Tasks operate on Python objects, the pairing of the Tasks and datasets are encoded in the Quantum Graph. The input-output (IO) operations are abstracted away into a component called the Data Butler. The Butler isolates users from the underlying file organization, file types and related file access mechanisms. Butler resolves a dataset ID through the Registry and retrieves the data from a Datastore. In simplified terms, the Datastore is the data storage, a POSIX filesystem for example, while the Registry, an SQL database, stores the provenance, metadata, IDs and other dataset relationships. By adding support for cloud services to the Butler we effectively gain the ability to run Science Pipelines in the cloud from a single compute instance – whether local or in the cloud.
AWS
We opted to implement Simple Storage Service (S3) functionality for the Datastore. Amazon S3 is the high-availability, globally accessible, scalable object storage service offered by AWS.
We implemented PostgreSQL functionality for the Registry and then utilized the Relational Database Service (RDS) to easily launch managed databases in AWS.
The compute resources are allocated by using the Elastic Compute Cloud (EC2) service. EC2 provides secure compute capacity in form of instances. Instances are sorted into instance types and instance sizes where each instance type adheres to a certain resource scaling factor. For example, the latest generation of compute optimized instances (“c5”) allocate 2GB of memory per CPU but then come in various sizes such as 2vCPUs, 4GBs or 4vCPUs, 8GBs … 96 vCPUs and 192 GB memory etc.
There are several pricing strategies through which users are charged for EC2 instances: on-demand, spot-fleet and reserved. On-demand instances most closely resemble the AWS pay-for-what-you-use principle. Spot-instances are procured through a bidding process on a spot-instance market and thus can be acquired at an up to 80% lower price compared to on-demand instances. Unlike the on-demand instances however, with a 2 minute warning, spot instances can be reallocated, by AWS, from the user. The reserved instances are similar to a pre-paid cost structure and can yield 40-60% savings compared to on-demand.
Pegasus and HTCondor
To be able to scale, first we need a way to procure, monitor and manage EC2 compute instances. HTCondor Annex is an addition to HTCondor that allows users to do exactly that. Procured instances are automatically added to the HTCondor compute pool and then deallocated after some set time has elapsed or if they idle for longer than some set time.
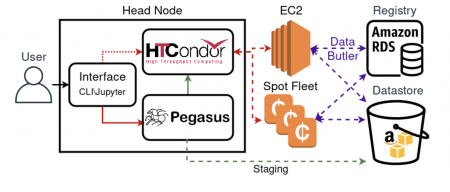
We convert the Quantum Graph to an abstract workflow using Pegasus API. The abstract workflow is converted to an executable workflow in the Pegasus planning stage and then executed by HTCondor’s DAGMan. More details on the planning stage configuration are discussed in the Preliminary Performance Testing section.
Migrating to Google Cloud Engine
Following the work described, Rubin decided to attempt to execute a similar workflow on Google Cloud. This required minimal code changes within Rubin Middleware component as GCE offers an interoperability service that will translate requests made to AWS S3 service into their GCE equivalents. While the services and cost rates are different between the two services the achieved deployment between AWS and GCE was similar.
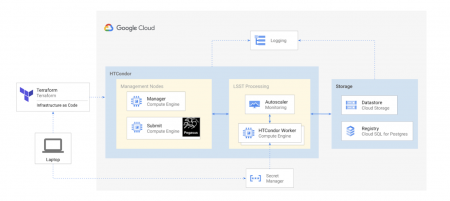
In October 2020, Rubin announced they will be running the Rubin Interim Data Facility, where they will process data collected in the initial stages of the survey (first ~2 years) on GCE.
Preliminary performance testing
We tested the system by running shortened Data Release Production (DRP) pipelines, products of which are calibrated images and source catalogs, on HyperSuprime Camera data. The DRP workflow is the pipeline Rubin will run on their data in production. The dataset represents approximately 11% of the number of nightly observations and is equivalent to ~2% of Rubin nightly data volume. In absolute terms the dataset consists of ~0.2TB from which ~3TB of output data is produced. For technical reasons the tests include an initialization Task that usually takes 25-30 minutes to execute and in principle would not have to be executed for runs that subsequently add to the same dataset collection.
After optimizing PostgreSQL instance cache and connection configuration and reducing the number of logs emitted by Rubin LSST Science Pipelines the biggest bottlenecks were the transfer of Quantum Graph node files, other log and relevant-to-execution files not in the purview of the Data Butler.
Because we used Pegasus exploring different ways to plan and execute the abstract workflow was essentially a trivial affair. Using the `nonsharedfs` Pegasus file system deployment, Site Catalog and a Replica Catalog we were able to bypass transfer of input files via a staging instance and instead were able to define an static staging site in an S3 Bucket. This allows workers to stage-in the Quantum Graph node configuration files directly from S3 and to stage-out the logs directly to S3.
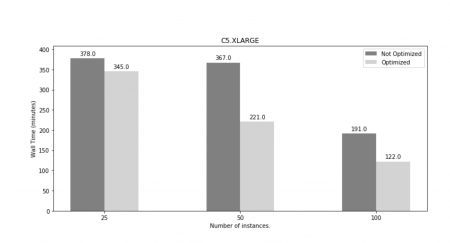
Adding horizontal clustering to the workflow was sufficient to alleviate various latency and delays related to the transfer and kickstart of the processing scripts. The DRP workflow jobs have drastically different expected execution times (from minutes to hours). This is because the early stages of the pipeline calibrate the images and produce source catalogs, which is an embarrassingly parallel problem, while the later stages deal with joint analysis of images and catalogs overlapping the same area of the sky which requires coalescing and processing of the data oo a single node. Finding the optimal cluster size and count we were able to achieve a nearly 50% decrease in the total wall time of our workflow. The reduction in total wall time per workflow translates directly to cost per workflow reduction due to AWS pricing policy for on-demand instances.
Configuring the Site Catalog consists of, at best, a 2-3 line long definition and the creation of the Pegasus Replica Catalog, which, while large, was also trivial as all it does is maps the logical file names in the DAX to physical location of our data in the S3 Bucket. Clustering is performed by specifying the number and size of clusters and adding a `–cluster horizontal` option to the Pegasus plan command.
Preliminary cost estimates
We evaluated execution across different cluster sizes, different instance types and sizes and different workflow executions and find that the cost per workflow remains approximately constant. As mentioned, this is not surprising due to the pay-for-what-you-use AWS policy. Increasing the number of workers and/or selecting more powerful EC2 instances decreases the total wall time while the cost remains constant since the higher costs of such compute pools are offset by the shorter duration they are being charged for.
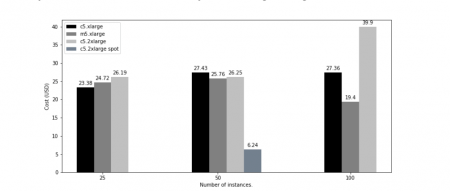
We attempted to construct cost estimate comparison for compute resources only for in-cloud vs on-premise deployments. We estimate, assuming the use of on-demand instances and Data Release Production workflow, the yearly cost of in-cloud Rubin operations lie in the 600 000 to 900 000 USD range. This price estimate is comparable to Rubin on-premises compute resource deployment cost estimate of 700 000 USD. Using the reserved instance pricing options and/or the use of spot-fleet instances, for the appropriate jobs in the workflow, could bring the in-cloud deployment lower by another 40-60%.
These estimates, however, do not include the long term data storage or data transfer fees. Storing 1TB/month in S3 Standard costs approximately 23 USD/month. The same 1TB of data can be stored in S3 Glacier service for approximately 4USD/month. Additional charges may apply depending on the number of HTTP requests made to the Bucket. For example, making 1 million PUT, COPY, POST, LIST requests to an S3 Standard Bucket cost, approximately, additional 5 USD, while making the same requests to an S3 Glacier Bucket cost an additional 50USD. Cost of data transfer into and in-between many AWS services, such as between S3 and EC2 service in the same availability zone, remains free. Therefore storage costs remain very use-specific and the optimal approach to minimizing transfer costs is to perform data egress as a single operation at the end of processing using an appropriate service such as AWS DirectConnect, Snowball, or in case of datasets at the scale of 100s of PBs – Snowmobile.
Next steps
We intend to continue the development of the described system on AWS by providing Packer and Terraform infrastructure-as-a-service scripts that are able to provide a continuous infrastructure build and deployment service capable of following the latest development efforts of Rubin. We aim to deliver a simpler way of launching and experimenting with the described system by providing both automated deployment as well as hosting the data and the infrastructure on which we would maintain an ongoing demo of Rubin on AWS. As we continue our efforts, we aim to provide all the relevant infrastructure, demos and example documentation in our RubinAWS GitHub repository.
Alongside the infrastructure plan to deliver additional functionality to the system to improve user experience by adopting and integrating HTCondor, Pegasus and the required AWS tooling with a Jupyter Notebook environment. Our objective is to provide Astronomers with a more familiar environment than the classic command-line prompt as well as providing the convenience tooling required to quickly and more easily create their own Rubin data repositories out of raw data collections.
As Rubin continues their development and work on the Interim Data Facility we plan on continuing to cooperation with them in hopes of finding and/or contributing solutions to, what are currently the biggest challenges to affordable scaling in the cloud – the costs of large centralized long-lived Registries and single-tiered Datastores.
Publications
D. Bektesevic, H. F. Chiang, et. al. A Gateway to Astronomical Image Processing: Vera C. RubinObservatory LSST Science Pipelines on AWS, https://arxiv.org/abs/2011.06044 , 2020
H.F. Chiang, D. Bektesevic, and the AWS-PoC team, “AWS Proof of Concept Project Report.” https://dmtn-137.lsst.io, 2020
H. F. Chiang, K. T. Liam, “Report of Google Cloud Proof of Concept” https://dmtn-157.lsst.io, 2020
H. F. Chiang, F. Huang et. al. Running Astronomical Pipelines with HTCondor, https://www.youtube.com/watch?v=CQgLEWZ_E1c